Documentation
Table of Contents
3 エスカレーション
概要
エスカレーションで、通知を送信したりリモートコマンドを実行するカスタムシナリオを作成できます。
実際面で、これは次のようなことを意味します:
- 新しい障害がユーザーにすぐに通知される
- 障害が解決されるまで通知が繰り返される
- 通知の送信を遅らせられる
- 他の「もっと高い」ユーザーグループに通知がエスカレーションされる
- すぐに、または障害がある程度の期間解決されないときにリモートコマンドが実行できる
- リカバリのメッセージが送信される
エスカレーションステップに基づいてアクションがエスカレーションされます。各ステップは持続時間を持っています。
各ステップのデフォルトの持続時間とカスタムの持続時間の両方を定義することができます。1ステップあたりの最小の継続時間は60秒です。
どのステップからでも、通知の送信やコマンドの実行といったアクションを開始できます。
ステップ1は即時のアクションです。アクションを遅らせたければ、そのアクションを後のステップに割り当てます。それぞれのステップで、複数のアクションが定義可能です。
エスカレーションのステップの数に制限はありません。
エスカレーションは、オペレーションの設定時に定義されます。
異なるエスカレーションが近い期間で連続していたりオーバーラップしている場合は、それぞれの新しいエスカレーションが前のエスカレーションにとってかわって実行されますが、最新のエスカレーションのステップは常に前のエスカレーション上で実行されます。トリガーの障害の評価「毎に」生成されるイベントで実行されるアクションでは、このふるまいは妥当です。
エスカレーションの例
例1
「MySQL administrators」グループに繰り返しの通知を、30分に1回(全体で5回)送信する。これを設定するには次のことをおこないます:
- 一般のアクションの属性で、デフォルトのエスカレーション期間を「1800」秒(30分)と設定
- [オペレーション]タブで、エスカレーションのステップを、「1」「から」「5」「まで」と設定
- メッセージの受信者としてとして「MySQL administrators」グループを選択

通知は、障害が発生した後(もちろん、障害がすぐに解決されなければ)0時間、30分、1時間、1時間30分、2時間に送信されます。
このエスカレーションシナリオでは、障害が解決されてリカバリメッセージが設定されていれば、少なくとも1つの障害メッセージを受信した人に、リカバリメッセージが送信されます。
アクティブなエスカレーションを生成したトリガーが無効になった場合、Zabbix が、通知を受けた人全員に、それに関する情報のメッセージを送信します。
例2
長時間の障害に関する通知の送信を遅らせます。これを設定するには、次のことをおこないます:
- 一般のアクションの属性でデフォルトのエスカレーションの期間を「36000」秒(10時間)に設定
- [オペレーション]タブで、エスカレーションのステップを「2」「から」「2」「まで」と設定

通知は、エスカレーションにシナリオのステップ2で送信されるだけです。または障害発生から10時間がたってから送信されます。
メッセージの本文は「10時間以上も障害状態だよ!」といった言葉にカスタマイズすることができます。
例3
上司に障害をエスカレーションする。
上記の1つめの例で、MySQLの管理者に対する定期的なメッセージの送信を設定しました。この場合、障害がデータベース管理者にエスカレーションされる前に、管理者は4つのメッセージを受信します。障害がまだ認識されていなくて、誰もそれについて対処していないと推測されるときにのみ、データベース管理者がメッセージを受信します。
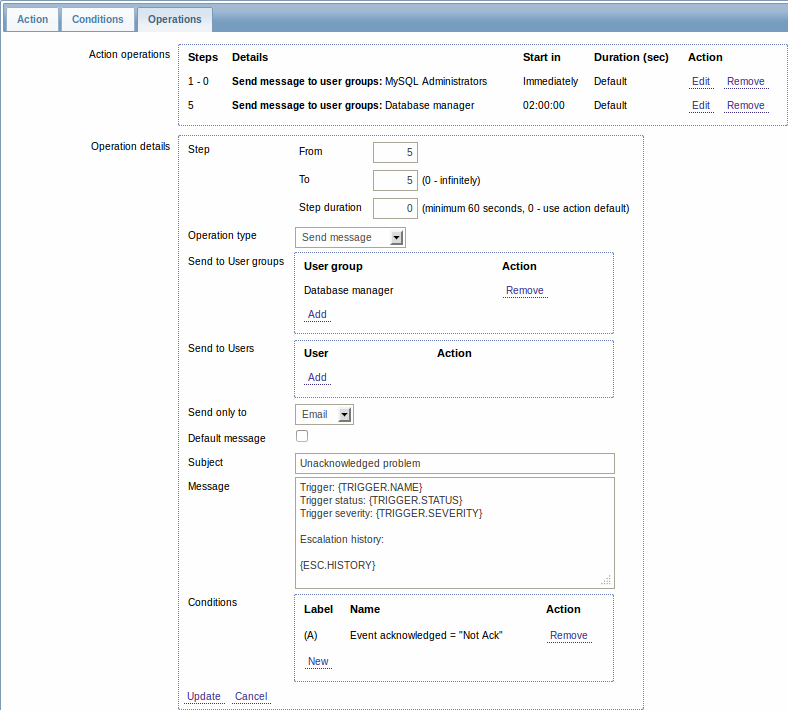
メッセージ内での{ESC.HISTORY}マクロの使用について憶えておいてください。そのマクロは、送信された通知や、実行されたコマンドなど、このエスカレーションで前に実行されたすべてのステップの情報を含みます。
例4
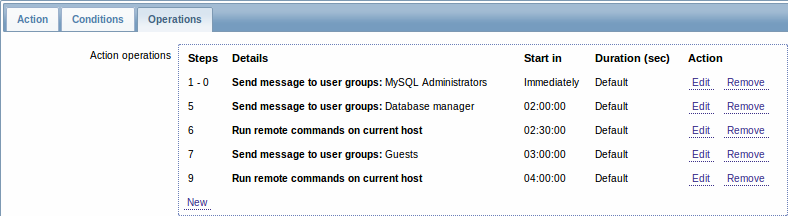
より複雑なシナリオです。MySQLの管理者に複数のメッセージを送信した後で、ZabbixがMySQL データベースを再スタートしようとしているということを管理者にエスカレーションします。それは、その障害が2時間30分の間続いていて、認識されなかった場合におこなうようにします。
さらに30分後も、障害がまだ存在していたら、Zabbixがすべてのゲストユーザーにメッセージを送信します。
これが助けにならなければ、さらに1時間後、IPMIコマンドを使用して、Zabbixが MySQL データベースとともにサーバをリブート(2番目のリモートコマンド)します。
例5
1つのステップにいくつかのオペレーションが割り当てられ、カスタムの実行間隔が使用されたエスカレーションの例。デフォルトのエスカレーションの期間は30分です。
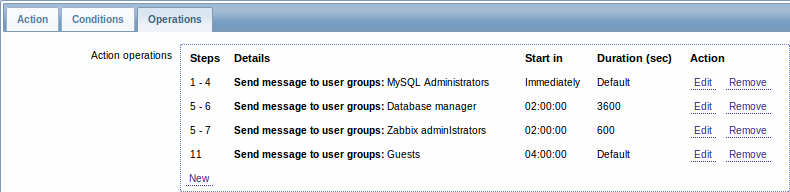
以下のように通知が送信されます:
- MySQL管理者に、障害発生から、0時、30分、1時間、1時間30分で
- Zabbix 管理者に、障害発生から2時間、2時間10分、2時間20分、2時間30分で(600秒の設定のカスタムのステップの持続時間)
- データベース管理者に、2時間と時間10分で(上記の600秒の短いカスタムステップの継続時間が、
- ここで設定されようとした3600秒の長いカスタムステップを上書き)
- ゲストユーザーに、障害発生から4時間後に(ステップ8と11の間に返ってくる、デフォルトの間隔は30分)
本ページは2013/05/05時点の原文を基にしておりますので、内容は必ずしも最新のものとは限りません。
最新の情報は右上の「Translations of this page」から英語版を参照してください。