Documentation
Table of Contents
3 Découverte de bas niveau
Aperçu
La découverte de bas niveau permet de créer automatiquement des éléments, des déclencheurs et des graphiques pour différentes entités sur un ordinateur. Par exemple, Zabbix peut démarrer automatiquement la surveillance des systèmes de fichiers ou des interfaces réseaux sur votre ordinateur, sans qu'il soit nécessaire de créer manuellement des éléments pour chaque système de fichiers ou interface réseau. De plus, il est possible de configurer Zabbix pour qu'il supprime automatiquement les entités inutiles en fonction des résultats réels de la découverte effectuée périodiquement.
Un utilisateur peut définir ses propres types de découverte, à condition de suivre un protocole JSON particulier.
L'architecture générale du processus de découverte est la suivante.
Tout d'abord, un utilisateur crée une règle de découverte dans la colonne "Configuration" → "Modèles" → "Découverte". Une règle de découverte consiste en (1) un élément qui découvre les entités nécessaires (par exemple, des systèmes de fichiers ou des interfaces réseau) et (2) des prototypes d'éléments, de déclencheurs et de graphiques qui doivent être créés en fonction de la valeur de cet élément.
Un élément qui découvre les entités nécessaires est comme un élément standard vu ailleurs : le serveur demande à un agent Zabbix (ou quel que soit le type d'élément défini) une valeur de cet élément, l'agent répond avec une valeur textuelle. La différence est que la valeur avec laquelle l'agent répond doit contenir une liste d'entités découvertes dans un format JSON spécifique. Bien que les détails de ce format ne soient importants que pour les développeurs de vérifications de découverte personnalisées, il est nécessaire de savoir que la valeur renvoyée contient une liste de paires macro → valeur. Par exemple, l'élément "net.if.discovery" peut renvoyer deux paires : "{#IFNAME}" → "lo" et "{#IFNAME}" → "eth0".
Ces macros sont utilisées dans les noms, les clés et les autres champs prototypes où elles sont ensuite remplacées par les valeurs reçues pour créer des éléments réels, des déclencheurs, des graphiques ou même des hôtes pour chaque entité découverte. Consultez la liste complète des options d'utilisation des macros LLD.
Lorsque le serveur reçoit une valeur pour un élément de découverte, il examine les paires macro → valeur et génère pour chaque paire des éléments réels, des déclencheurs et des graphiques, en fonction de leurs prototypes. Dans l'exemple avec "net.if.discovery" ci-dessus, le serveur générerait un ensemble d'éléments, de déclencheurs et de graphiques pour l'interface loopback "lo" et un autre ensemble pour l'interface "eth0".
Notez que depuis ** Zabbix 4.2 **, le format du JSON renvoyé par les règles de découverte de bas niveau a été modifié. Il n'est plus prévu que le JSON contienne l'objet "data". La découverte de bas niveau acceptera désormais un JSON normal contenant un tableau, afin de prendre en charge de nouvelles fonctionnalités telles que le prétraitement de la valeur d'élément et les chemins personnalisés vers les valeurs de macro de découverte de bas niveau dans un document JSON.
Les clés de découverte intégrées ont été mises à jour pour renvoyer un tableau de lignes LLD à la racine du document JSON. Zabbix extraira automatiquement une macro et une valeur si un champ de tableau utilise la syntaxe {#MACRO} comme clé. Toute nouvelle vérification de découverte native utilisera la nouvelle syntaxe sans les éléments "data". Lors du traitement d'une valeur de découverte de bas niveau, la racine est d'abord localisée (tableau à $. ou $.data).
Bien que l'élément "data" ait été supprimé de tous les éléments natifs liés à la découverte, pour des raisons de rétrocompatibilité, Zabbix acceptera toujours la notation JSON avec un élément "data", bien que son utilisation soit déconseillée. Si le JSON contient un objet avec un seul élément de tableau "data", il extraira automatiquement le contenu de l'élément en utilisant JSONPath $.data. La découverte de bas niveau accepte désormais les macros LLD facultatives définies par l'utilisateur avec un chemin personnalisé spécifié dans la syntaxe JSONPath.
Suite aux changements ci-dessus, les nouveaux agents ne pourront plus fonctionner avec un ancien serveur Zabbix.
Voir aussi : Entités découvertes
Configuration de la découverte de bas niveau
Nous allons illustrer la découverte de bas niveau en nous basant sur un exemple de découverte de système de fichiers.
Pour configurer la découverte, procédez comme suit :
- Aller dans : Configuration → Modèles ou Hôtes
- Cliquez sur Découverte dans la ligne d'un modèle/hôte approprié.
- Cliquez sur Créer une règle de découverte dans le coin supérieur droit de l'écran.
- Remplissez le formulaire de règle de découverte avec les détails requis
Règle de découverte
Le formulaire de règle de découverte contient cinq onglets, représentant, de gauche à droite, le flux de données lors de la découverte :
- Règle de découverte - spécifie, surtout, l'élément intégré ou le script personnalisé pour récupérer les données de découverte
- Prétraitement - applique un prétraitement aux données découvertes
- Macros LLD - permet d'extraire certaines valeurs de macro à utiliser dans les éléments découverts, les déclencheurs, etc.
- Filtres - permet de filtrer les valeurs découvertes
- Surcharge - permet de modifier des éléments, des déclencheurs, des graphiques ou des prototypes d'hôte lors de l'application à des objets découverts spécifiques
L'onglet Règle de découverte contient la clé d'élément à utiliser pour la découverte (ainsi que certains attributs généraux de la règle de découverte) :
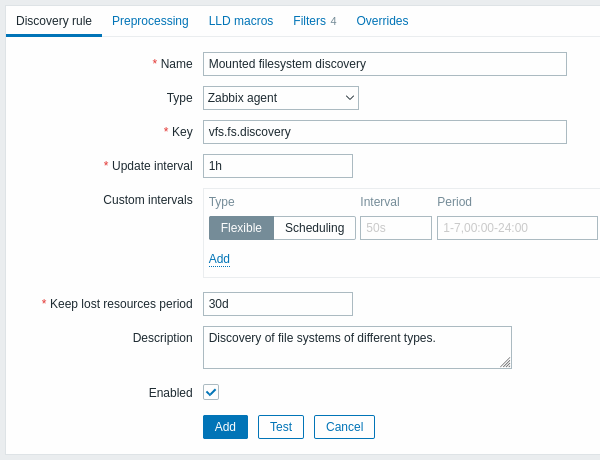
Tous les champs de saisie obligatoires sont marqués d'un astérisque rouge.
| Paramètre | Description |
|---|---|
| Nom | Nom de la règle de découverte. |
| Type | Le type de vérification pour effectuer la découverte Dans cet exemple, nous utilisons une clé d'élément agent Zabbix. La règle de découverte peut également être un élément dépendant. Elle ne peut pas dépendre d'une autre règle de découverte. Pour un élément dépendant, sélectionnez le type respectif (Élément dépendant) et spécifiez l'élément maître dans le champ 'Élément maitre'. L'élément maître doit exister. |
| Clé | Saisir la clé de l'élément de découverte (jusqu'à 2 048 caractères). Par exemple, vous pouvez utiliser la clé d'élément intégrée "vfs.fs.discovery" pour renvoyer un JSON avec la liste des systèmes de fichiers présents sur l'ordinateur et leur types. Notez qu'une autre option pour la découverte du système de fichiers utilise les résultats de la découverte par la clé d'agent "vfs.fs.get", prise en charge depuis Zabbix 4.4.5 (voir l'exemple). |
| Intervalle d'actualisation | Ce champ spécifie la fréquence à laquelle Zabbix effectue la découverte. Au début, lorsque vous configurez simplement la découverte de système de fichiers, vous pouvez définir un intervalle réduit, mais une fois que vous savez que cela fonctionne, vous pouvez le définir sur 30 minutes ou plus, car les systèmes de fichiers ne changent généralement pas très souvent. Les suffixes temporels sont supportés, ex : 30s, 1m, 2h, 1d, depuis Zabbix 3.4.0. Les macros utilisateurs sont supportées, depuis Zabbix 3.4.0. Remarque : L'intervalle de mise à jour ne peut être défini sur '0' que s'il existe des intervalles personnalisés avec une valeur différente de zéro. S'il est défini sur '0' et qu'un intervalle personnalisé (flexible ou planifié) existe avec une valeur différente de zéro, l'élément sera interrogé pendant la durée de l'intervalle personnalisé. Notez que pour une règle de découverte existante, la découverte peut être effectuée immédiatement en appuyant sur le bouton Vérifier maintenant. |
| Intervalle personnalisé | Vous pouvez créer des règles personnalisées pour vérifier l'élément : Flexible - créer une exception à l'intervalle d'actualisation (intervalle avec une fréquence différente) Planification - créez un calendrier d'interrogation personnalisé. Pour plus d'informations, voir Intervalles personnalisés. La planification est supportée depuis Zabbix 3.0.0. |
| Période de conservation des ressources perdues | Ce champ vous permet de spécifier la durée pendant laquelle l'entité découverte sera conservée (elle ne sera pas supprimée) une fois que son statut de découverte deviendra "Plus découvert" (entre 1 heure et 25 ans ; ou "0"). Les suffixes temporels sont supportés, ex : 2h, 1d, depuis Zabbix 3.4.0. Les macros utilisateurs sont supportées, depuis Zabbix 3.4.0. Remarque : Si la valeur est "0", les entités seront immédiatement supprimées. L'utilisation de "0" n'est pas recommandée, car une modification incorrecte du filtre risque de se retrouver dans l'entité en cours de suppression avec toutes les données historiques. |
| Description | Entrez une description. |
| Activé | Si coché, la règle sera traitée. |
L'historique des règles de découverte n'est pas conservé.
Prétraitement
L'onglet Prétraitement permet de définir des règles de transformation à appliquer au résultat de la découverte. Une ou plusieurs transformations sont possibles dans cette étape. Les transformations sont exécutées dans l'ordre dans lequel elles sont définies. Tout le prétraitement est effectué par le serveur Zabbix.
Voir également :
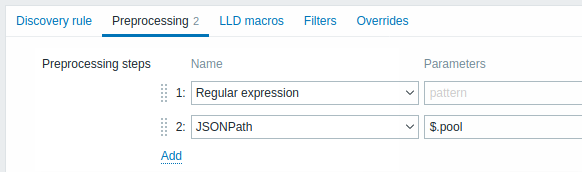
| Type | ||
|---|---|---|
| Transformation | Description | |
| Texte | ||
| Expression régulière | Faire correspondre la valeur reçue à l'expression régulière <motif> et remplacez la valeur par la <sortie> extraite. L'expression régulière prend en charge l'extraction d'un maximum de 10 groupes capturés avec la séquence \N. Paramètres : motif - expression régulière sortie - modèle de formatage de sortie. Une séquence d'échappement \N (où N=1…9) est remplacée par le Nième groupe correspondant. Une séquence d'échappement \0 est remplacée par le texte correspondant. Si vous cochez la case Personnalisé en cas d'échec, il est possible de spécifier des options de gestion des erreurs personnalisées : soit pour ignorer la valeur, soit pour définir une valeur spécifiée, soit pour définir un message d'erreur spécifié. |
|
| Remplacer | Trouver la chaîne de recherche et la remplacer par une autre (ou rien). Toutes les occurrences de la chaîne de recherche seront remplacées. Paramètres : chaîne recherchée - la chaîne à rechercher et à remplacer, sensible à la casse (obligatoire) remplacement - la chaîne par laquelle remplacer la chaîne de recherche. La chaîne de remplacement peut également être vide, ce qui permet de supprimer la chaîne de recherche lorsqu'elle est trouvée. Il est possible d'utiliser des séquences d'échappement pour rechercher ou remplacer les sauts de ligne, les retours chariot, les tabulations et les espaces "\n \r \t \s" ; la barre oblique inverse peut être échappée sous la forme "\\" et les séquences d'échappement peuvent être échappées sous la forme "\\n". L'échappement des sauts de ligne, des retours chariot et des tabulations est automatiquement effectué lors de la découverte de bas niveau. Pris en charge depuis 5.0.0. |
|
| Données structurées | ||
| JSONPath | Extraire une valeur ou un fragment de données JSON à l'aide de la fonctionnalité JSONPath. Si vous cochez la case Personnalisé en cas d'échec, l'élément ne deviendra pas non pris en charge en cas d'échec de l'étape de prétraitement et il est possible de spécifier des options de gestion des erreurs personnalisées : soit pour ignorer la valeur, soit pour définir une valeur spécifiée, soit pour définir un message d'erreur spécifié . |
|
| XPath XML | Extraire une valeur ou un fragment de données XML à l'aide de la fonctionnalité XPath. Pour que cette option fonctionne, le serveur Zabbix doit être compilé avec le support libxml. Exemples : number(/document/item/value) extraira 10 de <document><item><value>10</value></item></document>number(/document/item/@attribute) extraira 10 de<document><item attribute="10"></item></document>/document/item extraira <item><value>10</value></item> de <document><item><value>10</value></item></document>Notez que les espaces de noms ne sont pas pris en charge. Pris en charge depuis la version 4.4.0. Si vous cochez la case Personnalisé en cas d'échec, il est possible de spécifier des options de gestion des erreurs personnalisées : soit pour ignorer la valeur, soit pour définir une valeur spécifiée, soit pour définir un message d'erreur spécifié. |
|
| CSV vers JSON | Convertir les données du fichier CSV au format JSON. Pour plus d'informations, voir : Prétraitement CSV vers JSON. Pris en charge depuis 4.4.0. |
|
| XML vers JSON | Convertir les données au format XML en JSON. Pour plus d'informations, voir : Règles de sérialisation. Si vous cochez la case Personnalisé en cas d'échec, il est possible de spécifier des options de gestion des erreurs personnalisées : soit pour ignorer la valeur, soit pour définir une valeur spécifiée, soit pour définir un message d'erreur spécifié. |
|
| Custom scripts | ||
| Scripts personnalisés | ||
| JavaScript | Entrer le code JavaScript dans le bloc qui apparaît en cliquant dans le champ paramètre ou sur Ouvrir. Notez que la longueur JavaScript disponible dépend de la base de données utilisée. Pour plus d'informations, voir : Prétraitement JavaScript |
|
| Validation | ||
| Ne correspond pas à l'expression régulière | Spécifier une expression régulière à laquelle une valeur ne doit pas correspondre. Par exemple Error:(.*?)\.Si vous cochez la case Personnalisé en cas d'échec, il est possible de spécifier des options de gestion des erreurs personnalisées : soit pour ignorer la valeur, soit pour définir une valeur spécifiée, soit pour définir un message d'erreur spécifié. |
|
| Rechercher une erreur dans le JSON | Rechercher un message d'erreur au niveau de l'application situé dans JSONpath. Arrêtez le traitement en cas de succès et si le message n'est pas vide ; sinon, continuez le traitement avec la valeur qui était avant cette étape de prétraitement. Notez que ces erreurs de service externes sont signalées à l'utilisateur telles quelles, sans ajouter d'informations sur l'étape de prétraitement. Par exemple $.errors. Si un JSON comme {"errors":"e1"} est reçu, la prochaine étape de prétraitement ne sera pas exécutée.Si vous cochez la case Personnalisé en cas d'échec, il est possible de spécifier des options de gestion des erreurs personnalisées : soit pour ignorer la valeur, soit pour définir une valeur spécifiée, soit pour définir un message d'erreur spécifié. |
|
| Rechercher une erreur dans le XML | Rechercher un message d'erreur au niveau de l'application situé dans xpath. Arrêtez le traitement en cas de succès et si le message n'est pas vide ; sinon, continuez le traitement avec la valeur qui était avant cette étape de prétraitement. Notez que ces erreurs de service externe sont signalées à l'utilisateur telles quelles, sans ajouter d'informations sur l'étape de prétraitement. Aucune erreur ne sera signalée en cas d'échec de l'analyse du XML non valide. Pris en charge depuis la version 4.4.0. Si vous cochez la case Personnalisé en cas d'échec, il est possible de spécifier des options de gestion des erreurs personnalisées : soit pour ignorer la valeur, soit pour définir une valeur spécifiée, soit pour définir un message d'erreur spécifié. |
|
| Limitation | ||
| Ecarte les inchangés avec bit de vie | Ignorer une valeur si elle n'a pas changé au cours de la période définie (en secondes). Les valeurs entières positives sont prises en charge pour spécifier les secondes (minimum - 1 seconde). Des suffixes de temps peuvent être utilisés dans ce champ (par exemple 30s, 1m, 2h, 1d). Des macros utilisateur et des macros de découverte de bas niveau peuvent être utilisées dans ce champ. Une seule option de limitation peut être spécifiée pour un élément de découverte. Par exemple 1m. Si un texte identique est passé deux fois dans cette règle en 60 secondes, il sera supprimé.Remarque : La modification des prototypes d'éléments ne réinitialise pas la limitation. La limitation est réinitialisée uniquement lorsque les étapes de prétraitement sont modifiées. |
|
| Prometheus | ||
| Prometheus vers JSON | Convertire les métriques Prometheus requises en JSON. Voir Vérifications Prometheus pour plus de détails. |
|
Notez que si la règle de découverte a été appliquée à l'hôte via un modèle, le contenu de cet onglet est en lecture seule.
Macros personnalisées
L'onglet Macros LLD permet de spécifier des macros de découverte personnalisées de bas niveau.
Les macros personnalisées sont utiles dans les cas où le JSON renvoyé n'a pas les macros requises déjà définies. Ainsi, par exemple :
- La clé native
vfs.fs.discoverypour la découverte du système de fichiers renvoie un JSON avec des macros LLD prédéfinies telles que {#FSNAME}, {#FSTYPE}. Ces macros peuvent être utilisées dans l'élément, déclencher des prototypes (voir les sections suivantes de la page) directement ; la définition de macros personnalisées n'est pas nécessaire ; - L'élément d'agent
vfs.fs.getrenvoie également un JSON avec les données du système de fichiers, mais sans macros LLD prédéfinies. Dans ce cas, vous pouvez définir vous-même les macros et les mapper aux valeurs du JSON à l'aide de JSONPath :
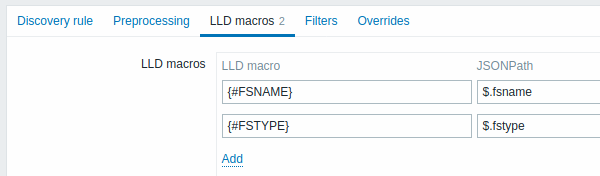
Les valeurs extraites peuvent être utilisées dans les éléments découverts, les déclencheurs, etc. Notez que les valeurs seront extraites du résultat de la découverte et de toutes les étapes de pré-traitement traitées jusqu'à présent.
| Paramètre | Description |
|---|---|
| Macro LLD | Nom de la macro de découverte de bas niveau, utilisant la syntaxe suivante : {#MACRO}. |
| JSONPath | Chemin utilisé pour extraire la valeur de macro LLD d'une ligne LLD, en utilisant la syntaxe JSONPath. Par exemple, $.foo extraira "bar" et "baz" de ce JSON : [{"foo":" bar"}, {"foo":"baz"}]Les valeurs extraites du JSON renvoyé sont utilisées pour remplacer les macros LLD dans les champs de prototype d'élément, de déclencheur, etc. JSONPath peut être spécifié à l'aide la notation pointée ou la notation parenthèse. La notation entre parenthèses doit être utilisée dans le cas de caractères spéciaux et d'Unicode, comme $['unicode + special chars #1']['unicode + special chars #2']. |
Filtre
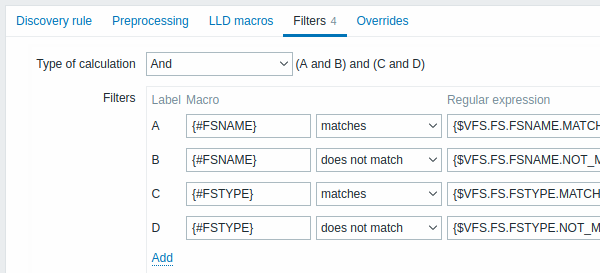
Un filtre peut être utilisé pour générer des éléments réels, des déclencheurs et des graphiques uniquement pour les entités qui correspondent aux critères. L'onglet Filtres contient des définitions de filtre de règle de découverte permettant de filtrer les valeurs de découverte :
| Paramètre | Description |
|---|---|
| Type of calcul | Les options suivantes de calcul des filtres sont disponibles : Et - tous les filtres doivent être réussis ; Ou - suffisant si un filtre est réussi ; Et/Ou - utilise And avec des noms de macro différents et Or avec le même nom de macro ; Expression personnalisée - offre la possibilité de définir un calcul personnalisé des filtres. La formule doit inclure tous les filtres de la liste. Limité à 255 symboles. |
| Filtres | Les opérateurs de condition de filtre suivants sont disponibles : correspond, ne correspond pas, existe, n'existe pas. Les opérateurs correspond et ne correspond pas attendent une expression régulière compatible Perl (PCRE). Par exemple, si vous n'êtes intéressé que par les systèmes de fichiers C:, D: et E:, vous pouvez mettre {#FSNAME} dans "Macro" et "^C|^D|^E" regular expression dans les champs de texte "Expression régulière". Le filtrage est également possible par type de système de fichiers à l'aide de la macro {#FSTYPE} (par exemple, "^ext|^reiserfs") et par type de lecteur (uniquement pris en charge par l'agent Windows) à l'aide de la macro {#FSDRIVETYPE} (par exemple, " fixed"). Vous pouvez saisir une expression régulière ou faire référence à une expression régulière globale dans le champ "Expression régulière". Pour tester une expression régulière, vous pouvez utiliser "grep -E", par exemple : for f in ext2 nfs reiserfs smbfs; do echo $f \| grep -E '^ext\|^reiserfs' \|\| echo "SKIP: $f"; doneLa macro {#FSDRIVETYPE} sous Windows est prise en charge depuis Zabbix 3.0.0. Les opérateurs existe et n'existe pas permettent de filtrer les entités en fonction de la présence ou de l'absence de la macro LLD spécifiée dans la réponse (supporté depuis la version 5.4.0). La définition de plusieurs filtres est prise en charge depuis Zabbix 2.4.0. Notez que si une macro du filtre est manquante dans la réponse, l'entité trouvée sera ignorée, sauf si une condition "n'existe pas" est spécifiée pour cette macro. Un avertissement sera affiché si l'absence de macro affecte le résultat d'expression. Par exemple si {#B} est manquant dans : {#A} matches 1 and {#B} matches 2 - donnera un avertissement {#A} matches 1 or {#B} matches 2 - pas d'avertissement. Cette logique d'avertissement flexible est prise en charge depuis Zabbix 6.0.11. |
Une erreur ou une faute de frappe dans l'expression régulière utilisée dans la règle LLD (par exemple, une expression régulière "File systems for discovery" incorrecte) peut entraîner la suppression de milliers d'éléments de configuration, de valeurs historiques et d'événements pour de nombreux hôtes.
La base de données Zabbix dans MySQL doit être créée en respectant la casse pour que les noms de système de fichiers qui ne diffèrent que par la casse soient découverts correctement.
Surcharge
L'onglet Surcharges permet de définir des règles pour modifier la liste des prototypes d'éléments, de déclencheurs, de graphiques et d'hôtes ou leurs attributs pour les objets découverts qui répondent à des critères donnés.
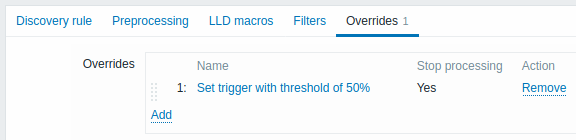
Les surcharges (le cas échéant) sont affichées dans une liste réorganisable par glisser-déposer et exécutés dans l'ordre dans lequel ils sont définis. Pour configurer les détails d'une nouvelle surcharge, cliquez sur  dans le bloc Surcharges. Pour modifier une surcharge existante, cliquez sur le nom de la surcharge. Une fenêtre contextuelle s'ouvrira permettant de modifier les détails de la règle de surcharge.
dans le bloc Surcharges. Pour modifier une surcharge existante, cliquez sur le nom de la surcharge. Une fenêtre contextuelle s'ouvrira permettant de modifier les détails de la règle de surcharge.
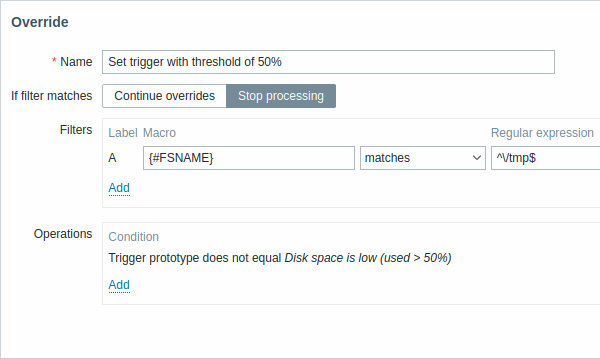
Tous les paramètres obligatoires sont signalés par des astérisques rouges.
| Paramètre | Description |
|---|---|
| Name | Un nom de surcharge unique (selon la règle LLD). |
| Si le filtre correspond | Définit si les surcharges suivantes doivent être traitées lorsque les conditions de filtre sont remplies : Continuer les surcharges - les surcharges suivantes seront traitées. Arrêter le traitement - les opérations précédentes ( le cas échéant) et cette surcharge sera exécutée, les surcharges suivantes seront ignorées pour les lignes LLD correspondantes. |
| Filtres | Détermine à quelles entités découvertes la surcharge doit être appliquée. Les filtres de surcharge sont traités après les filtres de la règle de découverte et ont la même fonctionnalité. |
| Opérations | Les opérations de surcharge sont affichées avec ces détails : Condition - un type d'objet (prototype d'élément/prototype de déclencheur/prototype de graphique/prototype d'hôte) et une condition à remplir (égal/n'est pas égal/contient/ne contient pas/correspond à/ne correspond pas) Action - les liens pour modifier et supprimer une opération sont affichés. |
Configurer une opération
Pour configurer les détails d'une nouvelle opération, cliquez sur dans le bloc Opérations. Pour modifier une opération existante, cliquez sur  à côté de l'opération. Une fenêtre contextuelle dans laquelle vous pouvez modifier les détails de l'opération s'ouvrira.
à côté de l'opération. Une fenêtre contextuelle dans laquelle vous pouvez modifier les détails de l'opération s'ouvrira.
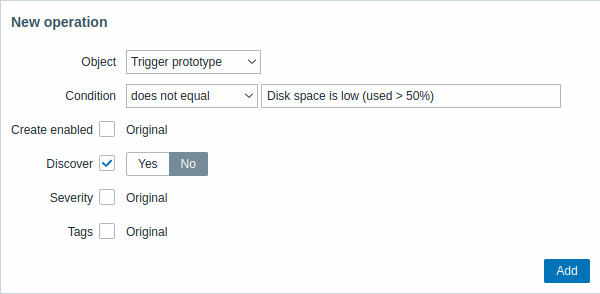
| Paramètre | Description | ||
|---|---|---|---|
| Objet | Quatre types d'objets sont disponibles : Prototype d'élément Prototype de déclencheur Prototype de graphique Prototype d'hôte |
||
| Condition | Permet de filtrer les entités auxquelles l'opération doit être appliquée. | ||
| Opérateur | Opérateurs pris en charge : égal - s'applique à ce prototype n'est pas égal - s'applique à tous les prototypes, sauf celui-ci contient - s'applique, si le nom du prototype contient une chaîne ne contient pas - s'applique, si le nom du prototype ne contient pas une chaîne correspond - s'applique, si le nom du prototype correspond à l'expression régulière ne correspond pas - s'applique, si le nom du prototype ne correspond pas à l'expression régulière |
||
| Motif | Une expression régulière ou une chaîne à rechercher. | ||
| Objet: Prototype d'élément | |||
| Créer activé | Lorsque la case est cochée, les boutons apparaîtront, permettant de remplacer les paramètres de prototype d'élément d'origine : Oui - l'élément sera ajouté dans un état activé. Non - le élément sera ajouté à une entité découverte mais dans un état désactivé. |
||
| Découvrir | Lorsque la case est cochée, les boutons apparaîtront, permettant de remplacer les paramètres du prototype d'élément d'origine : Oui - l'élément sera ajouté. Non - l'élément ne sera pas ajouté. |
||
| Intervalle d'actualisation | Lorsque la case est cochée, deux options apparaîtront, permettant de définir un intervalle différent pour l'élément : Délai - Intervalle de mise à jour de l'élément. Les macros utilisateur et les suffixes temporels (par exemple, 30s, 1m, 2h, 1d) sont pris en charge. Doit être défini sur 0 si Intervalle personnalisé est utilisé. Intervalle personnalisé - cliquez sur pour spécifier un intervalle flexible/planifié. Pour des informations détaillées, voir Intervalles personnalisés. |
||
| Période de stockage de l'historique | Lorsque la case est cochée, les boutons apparaissent, permettant de définir une période de stockage de l'historique différente pour l'élément : Ne pas conserver l'historique - si sélectionné, l'historique ne sera pas être stocké. Période de stockage - si sélectionné, un champ de saisie pour spécifier la période de stockage apparaîtra à droite. Les macros utilisateur et les macros LLD sont prises en charge. |
||
| Période de stockage des tendances | Lorsque la case est cochée, les boutons apparaissent, permettant de définir une période de stockage des tendances différente pour l'élément : Ne pas conserver les tendances - si sélectionné, les tendances ne seront pas être stocké. Période de stockage - si sélectionné, un champ de saisie pour spécifier la période de stockage apparaîtra à droite. Les macros utilisateur et les macros LLD sont prises en charge. |
||
| Tags | Lorsque la case est cochée, un nouveau bloc apparaîtra, permettant de spécifier des paires tag-valeur. Ces tags seront ajoutés aux tags spécifiés dans le prototype de l'élément, même si les noms de tag correspondent. |
||
| Objet : Prototype de déclencheur | |||
| Créer activé | Lorsque la case est cochée, les boutons apparaîtront, permettant de remplacer les paramètres originaux du prototype de déclencheur : Oui - le déclencheur sera ajouté dans un état activé. Non - le déclencheur sera ajouté à une entité découverte, mais dans un état désactivé. |
||
| Découvrir | Lorsque la case est cochée, les boutons apparaîtront, permettant de remplacer les paramètres originaux du prototype de déclencheur : Oui - le déclencheur sera ajouté. Non - le déclencheur ne sera pas ajouté. |
||
| Sévérité | Lorsque la case est cochée, des boutons de sévérité du déclencheur apparaîtront, permettant de modifier la sévérité du déclencheur. | ||
| Tags | Lorsque la case est cochée, un nouveau bloc apparaîtra, permettant de spécifier des paires tag-valeur. Ces tags seront ajoutés aux tags spécifiés dans le prototype du déclencheur, même si les noms de tag correspondent. |
||
| Objet : Prototype de graphique | |||
| Découvrir | Lorsque la case est cochée, les boutons apparaîtront, permettant de remplacer les paramètres originaux du prototype de graphique : Oui - le graphique sera ajouté. Non - le graphique ne sera pas ajouté . |
||
| Objet : Prototype d'hôte | |||
| Créer activé | Lorsque la case est cochée, les boutons apparaîtront, permettant de remplacer les paramètres du prototype d'hôte d'origine : Oui - l'hôte sera créé dans un état activé. Non - le l'hôte sera créé dans un état désactivé. |
||
| Découvrir | Lorsque la case est cochée, les boutons apparaîtront, permettant de remplacer les paramètres du prototype d'hôte d'origine : Oui - l'hôte sera découvert. Non - l'hôte ne sera pas découvert. |
||
| Lier les modèles | Lorsque la case est cochée, un champ de saisie pour spécifier les modèles apparaîtra. Commencez à saisir le nom du modèle ou cliquez sur Sélectionner à côté du champ et sélectionnez des modèles dans la liste dans une fenêtre contextuelle. Tous les modèles liés à un prototype hôte seront remplacés par les modèles de cette surcharge. |
||
| Tags | Lorsque la case est cochée, un nouveau bloc apparaîtra, permettant de spécifier des paires tag-valeur. Ces tags seront ajoutés aux tags spécifiés dans le prototype de l'hôte, même si les noms de tag correspondent. |
||
| Inventaire de l'hôte | Lorsque la case est cochée, les boutons apparaîtront, permettant de sélectionner un mode d'inventaire différent pour le prototype d'hôte : Désactivé - ne pas remplir l'inventaire de l'hôte Manuel - fournir les détails manuellement Automatique - remplir automatiquement les données d'inventaire de l'hôte en fonction des métriques collectées. |
||
Boutons de formulaire
Des boutons en bas du formulaire permettent d'effectuer plusieurs opérations.
 |
Ajouter une règle de découverte. Ce bouton n'est disponible que pour les nouvelles règles de découverte. |
 |
Mettre à jour les propriétés d'une règle de découverte. Ce bouton n'est disponible que pour les règles de découverte existantes. |
 |
Créer une autre règle de découverte basée sur les propriétés de la règle de découverte actuelle. |
 |
Effectuer immédiatement une découverte basée sur la règle de découverte. La règle de découverte doit déjà exister. Voir plus de détails. Notez que lors d'une découverte immédiate, le cache de configuration n'est pas mis à jour, donc le résultat ne reflétera pas les modifications très récentes apportées à la configuration de la règle de découverte. |
 |
Supprimer la règle de découverte. |
 |
Annuler la modification des propriétés de la règle de découverte. |
Entités découvertes
Les captures d'écran ci-dessous illustrent à quoi ressemblent les éléments, les déclencheurs et les graphiques découverts dans la configuration de l'hôte. Les entités découvertes sont précédées d'un lien orange vers une règle de découverte dont elles proviennent.
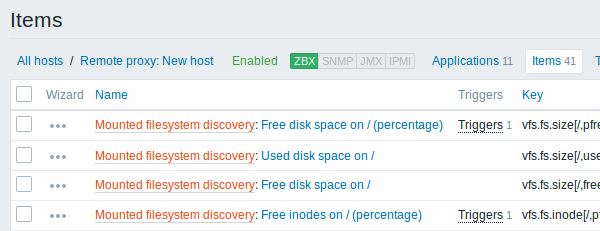
Notez que les entités découvertes ne seront pas créées s'il existe déjà des entités existantes avec les mêmes critères d'unicité, par exemple, un élément avec la même clé ou un graphique avec le même nom. Un message d'erreur s'affiche dans ce cas dans le frontend indiquant que la règle de découverte de bas niveau n'a pas pu créer certaines entités. La règle de découverte elle-même, cependant, ne deviendra pas non prise en charge car certaines entités n'ont pas pu être créées et ont dû être ignorées. La règle de découverte continuera à créer/mettre à jour d'autres entités.
Les éléments (de même que les déclencheurs et les graphiques) créés par une règle de découverte de bas niveau seront automatiquement supprimés si une entité découverte (système de fichiers, interface, etc.) cesse d'être découverte (ou ne passe plus le filtre). Dans ce cas, les éléments, les déclencheurs et les graphiques seront supprimés après les jours définis dans le champ Période de conservation des ressources perdues passés.
Lorsque les entités découvertes deviennent 'Plus découvertes', un indicateur de durée de vie s'affiche dans la liste des éléments. Déplacez le pointeur de votre souris dessus et un message s'affichera indiquant combien de jours il reste jusqu'à ce que l'élément soit supprimé.

Si des entités ont été marquées pour suppression, mais n'ont pas été supprimées au moment prévu (règle de découverte ou hôte d'élément désactivé), elles seront supprimées lors du prochain traitement de la règle de découverte.
Les entités contenant d'autres entités, qui sont marquées pour suppression, ne seront pas mises à jour si elles sont modifiées au niveau de la règle de découverte. Par exemple, les déclencheurs basés sur LLD ne seront pas mis à jour s'ils contiennent des éléments marqués pour suppression.
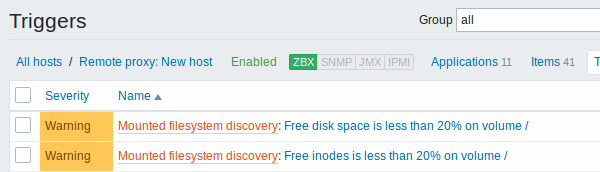
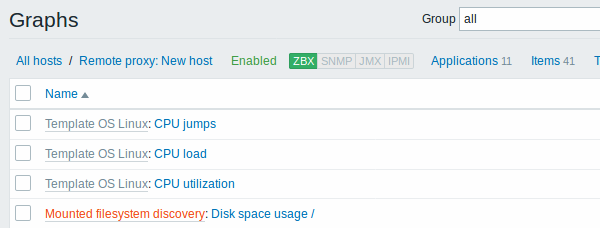
Autres types de découverte
Plus de détails et de procédures sur d'autres types de découvertes prêtes à l'emploi sont disponibles dans les sections suivantes :
- découverte des interfaces réseau;
- découverte des CPU et cœurs de CPU ;
- découverte des OID SNMP ;
- découverte des objets JMX;
- découverte à l'aide de requêtes SQL ODBC ;
- découverte des services Windows ;
- découverte des interfaces hôtes dans Zabbix.
Pour plus de détails sur le format JSON des éléments de découverte et un exemple d'implémentation de votre propre outil de découverte de système de fichiers avec un script Perl, consultez la création de règles LLD personnalisées.