Table of Contents
1 High availability
Overview
High availability (HA) is typically required in critical infrastructures that can afford virtually no downtime. So for any service that may fail there must be a failover option in place to take over should the current service fail.
Zabbix offers a native high-availability solution that is easy to set up and does not require any previous HA expertise. Native Zabbix HA may be useful for an extra layer of protection against software/hardware failures of Zabbix server or to have less downtime due to maintenance.
In the Zabbix high availability mode multiple Zabbix servers are run as nodes in a cluster. While one Zabbix server in the cluster is active, others are on standby, ready to take over if necessary.
Switching to Zabbix HA is non-committal. You may switch back to standalone operation at any point.
See also: Implementation details
Enabling high availability
Starting Zabbix server as cluster node
Two parameters are required in the server configuration to start a Zabbix server as cluster node:
- HANodeName parameter must be specified for each Zabbix server that will be an HA cluster node.
This is a unique node identifier (e.g. zabbix-node-01) that the server will be referred to in agent and proxy configurations. If you do not specify HANodeName, then the server will be started in standalone mode.
- NodeAddress parameter must be specified for each node.
The NodeAddress parameter (address:port) will be used by Zabbix frontend to connect to the active server node. NodeAddress must match the IP or FQDN name of the respective Zabbix server.
Restart all Zabbix servers after making changes to the configuration files. They will now be started as cluster nodes. The new status of the servers can be seen in Reports → System information and also by running:
zabbix_server -R ha_statusThis runtime command will log the current HA cluster status into the Zabbix server log (and to stdout):

Preparing frontend
Make sure that Zabbix server address:port is not defined in the frontend configuration (found in conf/zabbix.conf.php of the frontend files directory).

Zabbix frontend will autodetect the active node by reading settings from the nodes table in Zabbix database. Node address of the active node will be used as the Zabbix server address.
Proxy configuration
HA cluster nodes (servers) must be listed in the configuration of either passive or active Zabbix proxy.
For a passive proxy, the node names must be listed in the Server parameter of the proxy, separated by a comma.
Server=zabbix-node-01,zabbix-node-02For an active proxy, the node names must be listed in the Server parameter of the proxy, separated by a semicolon.
Server=zabbix-node-01;zabbix-node-02Agent configuration
HA cluster nodes (servers) must be listed in the configuration of Zabbix agent or Zabbix agent 2.
To enable passive checks, the node names must be listed in the Server parameter, separated by a comma.
Server=zabbix-node-01,zabbix-node-02To enable active checks, the node names must be listed in the ServerActive parameter. Note that for active checks the nodes must be separated by a comma from any other servers, while the nodes themselves must be separated by a semicolon, e.g.:
ServerActive=zabbix-node-01;zabbix-node-02Failover to standby node
Zabbix will fail over to another node automatically if the active node stops. There must be at least one node in standby status for the failover to happen.
How fast will the failover be? All nodes update their last access time (and status, if it is changed) every 5 seconds. So:
If the active node shuts down and manages to report its status as "stopped", another node will take over within 5 seconds.
If the active node shuts down/becomes unavailable without being able to update its status, standby nodes will wait for the failover delay + 5 seconds to take over
The failover delay is configurable, with the supported range between 10 seconds and 15 minutes (one minute by default). To change the failover delay, you may run:
zabbix_server -R ha_set_failover_delay=5mManaging HA cluster
The current status of the HA cluster can be managed using the dedicated runtime control options:
ha_status- log HA cluster status in the Zabbix server log (and to stdout)ha_remove_node=target- remove an HA node identified by its <target> - name or ID of the node (name/ID can be obtained from the output of running ha_status), e.g.:
zabbix_server -R ha_remove_node=zabbix-node-02Note that active/standby nodes cannot be removed.
ha_set_failover_delay=delay- set HA failover delay (between 10 seconds and 15 minutes; time suffixes are supported, e.g. 10s, 1m)
Node status can be monitored:
- in Reports → System information
- in the System information dashboard widget
- using the
ha_statusruntime control option of the server (see above).
The zabbix[cluster,discovery,nodes] internal item can be used for node discovery, as it returns a JSON with the high-availability node information.
Disabling HA cluster
To disable a high availability cluster:
- make backup copies of configuration files
- stop standby nodes
- remove the HANodeName parameter from the active primary server
- restart the primary server (it will start in standalone mode)
Upgrading HA cluster
To perform a major version upgrade for the HA nodes:
- stop all nodes;
- create a full database backup;
- if the database uses replication make sure that all nodes are in sync and have no issues. Do not upgrade if replication is broken.
- select a single node that will perform database upgrade, change its configuration to standalone mode by commenting out HANodeName and upgrade it;
- make sure that database upgrade is fully completed (System information should display that Zabbix server is running);
- restart the node in HA mode;
- upgrade and start the rest of nodes (it is not required to change them to standalone mode as the database is already upgraded at this point).
In a minor version upgrade it is sufficient to upgrade the first node, make sure it has upgraded and running, and then start upgrade on the next node.
Implementation details
The high availability (HA) cluster is an opt-in solution and it is supported for Zabbix server. The native HA solution is designed to be simple in use, it will work across sites and does not have specific requirements for the databases that Zabbix recognizes. Users are free to use the native Zabbix HA solution, or a third-party HA solution, depending on what best suits the high availability requirements in their environment.
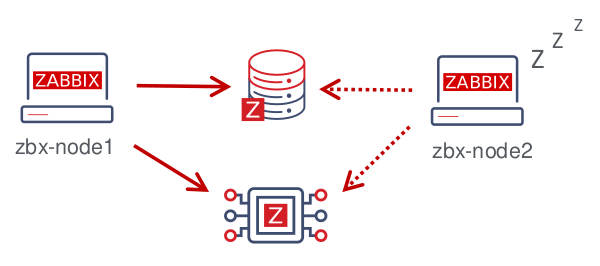
The solution consists of multiple zabbix_server instances or nodes. Every node:
- is configured separately
- uses the same database
- may have several modes: active, standby, unavailable, stopped
Only one node can be active (working) at a time. A standby node runs only one process - the HA manager. A standby node does no data collection, processing or other regular server activities; they do not listen on ports; they have minimum database connections.
Both active and standby nodes update their last access time every 5 seconds. Each standby node monitors the last access time of the active node. If the last access time of the active node is over 'failover delay' seconds, the standby node switches itself to be the active node and assigns 'unavailable' status to the previously active node.
The active node monitors its own database connectivity - if it is lost for more than failover delay-5 seconds, it must stop all processing and switch to standby mode. The active node also monitors the status of the standby nodes - if the last access time of a standby node is over 'failover delay' seconds, the standby node is assigned the 'unavailable' status.
The nodes are designed to be compatible across minor Zabbix versions.