
5 Escalado
Descripción general
Con los escalados puedes crear escenarios personalizados para enviar notificaciones o ejecutar comandos remotos.
En términos prácticos significa que:
- Los usuarios pueden ser informados sobre nuevos problemas inmediatamente.
- Las notificaciones se pueden repetir hasta que se resuelva el problema.
- El envío de una notificación puede retrasarse.
- Las notificaciones se pueden escalar a otro grupo de usuarios "superior".
- Los comandos remotos se pueden ejecutar inmediatamente o cuando no haya ningún problema. resuelto durante un largo período.
Las acciones se escalan según el paso de escalamiento. Cada paso tiene una duración en el tiempo.
Puede definir tanto la duración predeterminada como una duración personalizada de un paso individual. La duración mínima de un paso de escalado es 60 segundos.
Puede iniciar acciones, como enviar notificaciones o ejecutar comandos, desde cualquier paso. El primer paso es para acciones inmediatas. Si quiere retrasar una acción, puede asignarla a un paso posterior. Para cada paso, se pueden definir varias acciones.
El número de pasos de escalado no está limitado.
Los escalados se definen cuando se configura una operación. Los escalados solo se admiten para operaciones problemáticas, no para la recuperación.
Aspectos diversos del comportamiento de escalada
Consideremos lo que sucede en diferentes circunstancias si una acción contiene varios pasos de escalada.
| Situación | Comportamiento |
|---|---|
| El host en cuestión entra en mantenimiento después de que se envía la notificación de problema inicial | Dependiendo de la configuración Pausar operaciones para problemas suprimidos en acción configuración, todos los pasos de escalada restantes se ejecutan con un retraso causado por el período de mantenimiento o sin retraso. Un periodo de mantenimiento no cancela operaciones. |
| El período de tiempo definido en la condición de acción Período de tiempo finaliza después de que se envía la notificación inicial | Se ejecutan todos los pasos de escalamiento restantes. La condición Período de tiempo no puede detener las operaciones; tiene efecto respecto a cuándo se inician/no inician acciones, no operaciones. |
| Un problema comienza durante el mantenimiento y continúa (no se resuelve) después de que finaliza el mantenimiento | Dependiendo de la configuración Pausar operaciones para problemas suprimidos en acción configuración, todos los pasos de escalamiento se ejecutan desde el momento en que finaliza el mantenimiento o inmediatamente. |
| Un problema comienza durante un mantenimiento sin datos y continúa (no se resuelve) después de que finaliza el mantenimiento | Debe esperar a que se dispare el disparador, antes de que se ejecuten todos los pasos de escalamiento. |
| Las diferentes escaladas siguen en estrecha sucesión y se superponen | La ejecución de cada nueva escalada reemplaza la escalada anterior, pero por lo menos para un paso de escalada que siempre se ejecuta en la escalada anterior. Este comportamiento es relevante en acciones sobre eventos que se crean con CADA evaluación de problema del disparador. |
| Durante una escalada en curso (como el envío de un mensaje), en función de cualquier tipo de evento: - la acción está deshabilitada Basado en el evento desencadenante: - el desencadenante está deshabilitado - el host o elemento está deshabilitado Basado en un evento interno acerca de los disparadores: - el disparador está deshabilitado Basado en un evento interno sobre los elementos/reglas de descubrimiento de bajo nivel: - el elemento está deshabilitado<br >- el host está deshabilitado |
Se envía el mensaje en curso y luego se envía un mensaje más sobre la escalada. El mensaje de seguimiento tendrá el texto de cancelación al principio del cuerpo del mensaje (NOTA: Escalamiento cancelado) nombrando el motivo (por ejemplo, NOTA: Escalado cancelado: acción '<Nombre de la acción>' deshabilitada). De esta forma se informa al destinatario que se cancela el escalamiento y no se ejecutarán más pasos. Este mensaje se envía a todos los que recibieron las notificaciones antes. El motivo de la cancelación también se registra en el archivo de registro del servidor (a partir de Nivel de depuración 3=Advertencia). Tenga en cuenta que el mensaje Escalación cancelada también se envía si las operaciones han finalizado, pero las operaciones de recuperación están configuradas y aún no se ejecutan. |
| Durante una escalada en curso (como el envío de un mensaje), la acción se elimina | No se envían más mensajes. La información se registra en el archivo de registro del servidor (a partir de Nivel de depuración 3=Advertencia), por ejemplo: escalación cancelada: ID de acción: 334 eliminado |
Ejemplos de escalamiento
Ejemplo 1
Envío de una notificación repetida una vez cada 30 minutos (5 veces en total) a un grupo de "Administradores de MySQL". Para configurar:
- En la pestaña Operaciones, establezca la Duración del paso de operación predeterminada en "30 m" (30 minutos).
- Establezca los Pasos de escalado para que sea del "1" al "5".
- Seleccione el grupo "Administradores de MySQL" como destinatarios del mensaje.
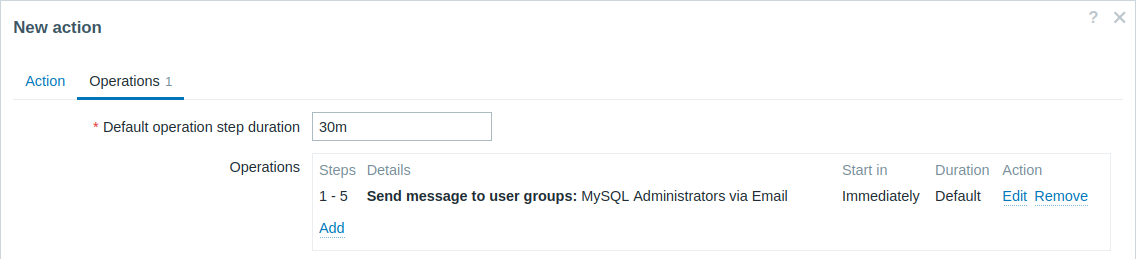
Las notificaciones se enviarán a las 0:00, 0:30, 1:00, 1:30, 2:00 horas después de que el problema comienza (a menos, por supuesto, que el problema se resuelva antes).
Si el problema se resuelve y se configura un mensaje de recuperación, se enviará a aquellos que recibieron al menos un mensaje de problema dentro de este escenario de escalada.
Si el iniciador que generó un escalado activo es desactivado, Zabbix envía un mensaje informativo al respecto a todos aquellos que ya han recibido notificaciones.
Ejemplo 2
Envío de una notificación retrasada sobre un problema de larga duración. A configurar:
- En la pestaña Operaciones, establezca la Duración del paso de operación predeterminada en "10h" (10 horas).
- Establezca los Pasos de escalado para que sea de "2" a "2".
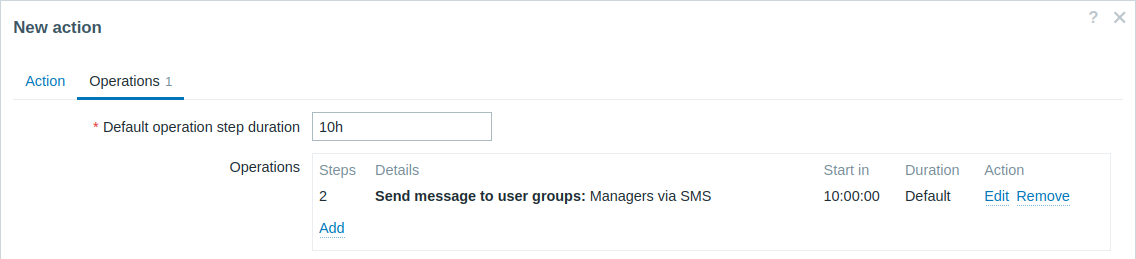
Solo se enviará una notificación en el Paso 2 del escenario de escalado, o 10 horas después de que comience el problema.
Puede personalizar el texto del mensaje con algo como "El problema tiene más de 10 horas".
Ejemplo 3
Escalando el problema al Jefe.
En el primer ejemplo anterior configuramos el envío periódico de mensajes a los administradores de MySQL. En este caso, los administradores obtendrán cuatro mensajes antes de que el problema se escale al administrador de la base de datos. Tenga en cuenta que el administrador recibirá un mensaje sólo en caso de que el problema no se. haya reconocido, supuestamente nadie está trabajando en ello.
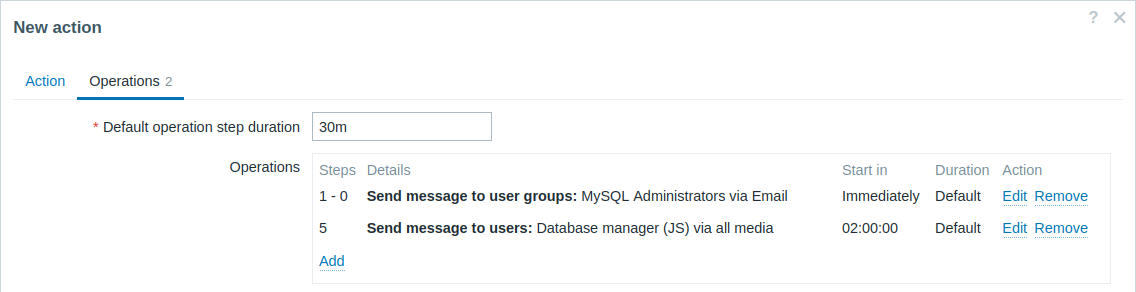
Detalles de la Operación 2:
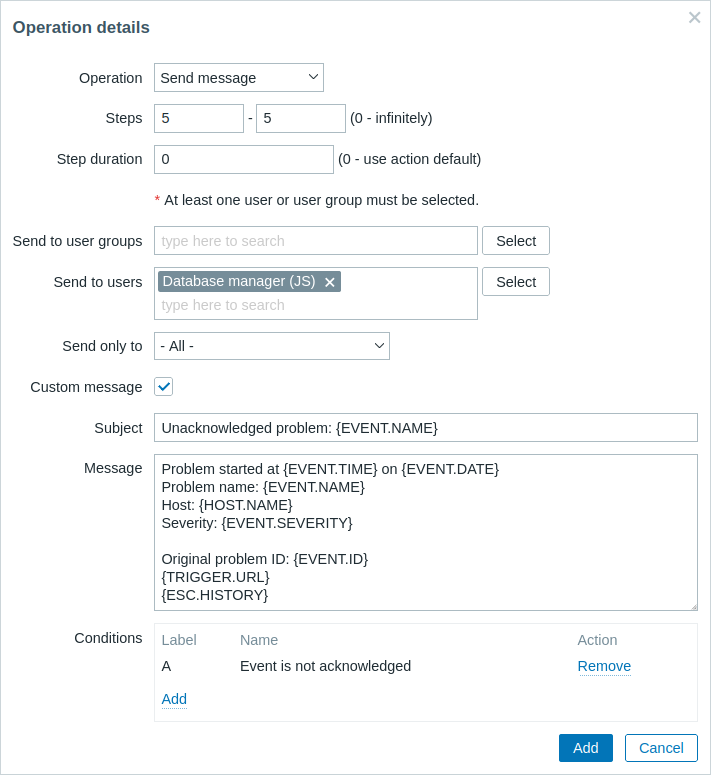
Tenga en cuenta el uso de la macro {ESC.HISTORY} en el mensaje personalizado. La macro contendrá información sobre todos los pasos ejecutados previamente en esta escalada, como notificaciones enviadas y comandos ejecutados.
Ejemplo 4
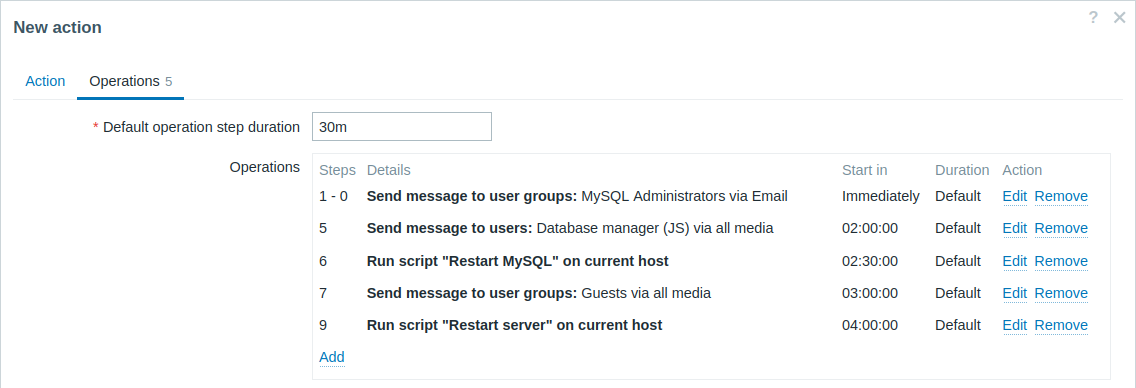
Un escenario más complejo. Después de múltiples mensajes a los administradores de MySQL y escalamiento al administrador, Zabbix intentará reiniciar MySQL base de datos. Sucederá si el problema existe durante 2:30 horas y se no ha sido reconocido.
Si el problema persiste, después de otros 30 minutos, Zabbix enviará un mensaje a todos los usuarios invitados.
Si esto no ayuda, después de otra hora, Zabbix reiniciará el servidor con la base de datos MySQL (segundo comando remoto) usando comandos IPMI.
Ejemplo 5
Una escalada con varias operaciones asignadas a un paso y usando intervalos personalizados. La duración predeterminada del paso de operación es de 30 minutos.
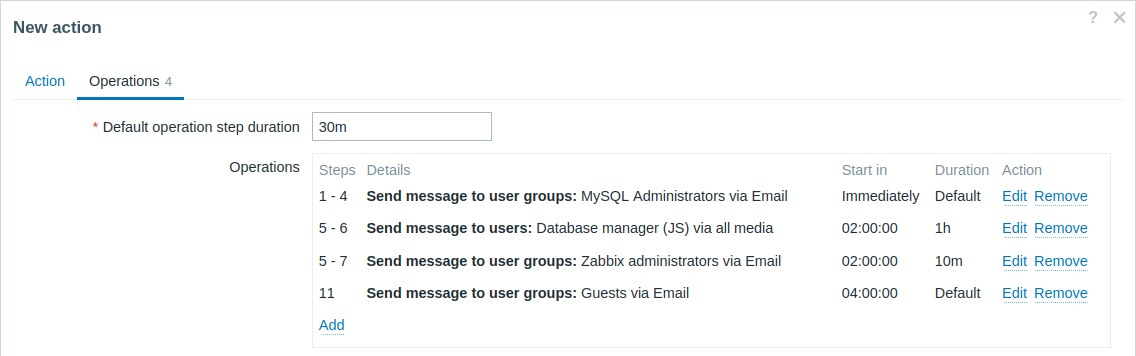
Las notificaciones se enviarán de la siguiente manera:
- A los administradores de MySQL a las 0:00, 0:30, 1:00, 1:30 después de que comience el problema.
- Al administrador de la base de datos a las 2:00 y 2:10. (y no a las 3:00; viendo que los pasos 5 y 6 se superponen con la siguiente operación, la duración del paso personalizado más corto de 10 minutos en la siguiente operación anula la duración del paso más largo de 1 hora que se intentó configurar aquí).
- A los administradores de Zabbix a las 2:00, 2:10, 2:20 después de que comience el problema (la duración del paso personalizado es de 10 minutos en funcionamiento).
- A los usuarios invitados a las 4:00 horas después del inicio del problema (la duración del paso predeterminada es de 30 minutos y regresa entre los pasos 8 y 11).