Documentation
Table of Contents
2 Детали предобработки значений элементов данных
Обзор
Предварительная обработка значений элементов данных позволяет задать и выполнять правила преобразований для полученных значений элементов данных.
Предварительная обработка управляется процессом менеджером предобработки, который добавлен в Zabbix с 3.4 версии, вместе с "workers" препроцессорами, которые выполняют шаги предобработки. Все значения (с и без предобработкой) с различных сборщиков данных проходят через менеджера предобработки перед тем, как добавляются в кэш истории. Для связи между сборщиками данных (поллерами, трапперами и т.д.) и процессами предобработки используется межпроцессорное взаимодействие (IPC) на основе сокета. Шаги предварительной обработки могут выполняться Zabbix сервером или Zabbix прокси, в зависимости от настроек элемента данных.
Обработка значений элементов данных
Для визуализации потока данных от источника данных к базе данных Zabbix мы можем использовать следующую упрощённую диаграму:
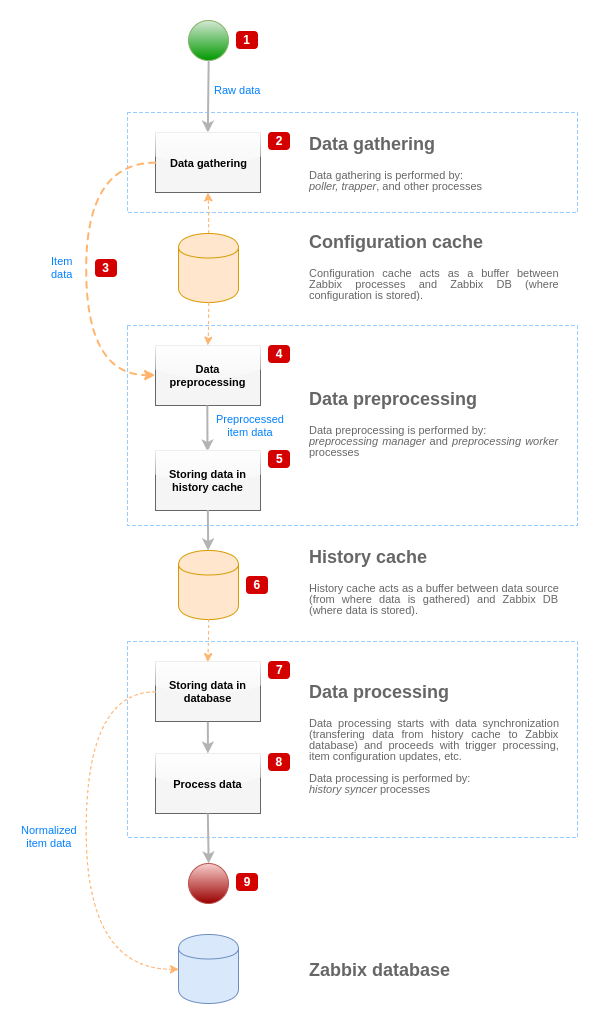
Диаграма выше показывает только процессы, объекты и действия, которые связаны с предварительной обработкой значений элементов данных в упрощенной форме. Диаграма не отображает изменения направлений при различных условиях, обработку ошибок или циклы. Локальный кэш данных в менеджере предобработки не отображается, так как он не влияет напрямую на поток данных. Целью этой диаграммы является отображение процессов, которые вовлечены в предобработку значений элементов данных, а также способ их взаимодействия.
- Сбор данных начинается с сырых данных от источника данных. В данный момент данные содержат только ID, штамп времени и значение (также может быть несколько значений)
- Не важно какой используется тип сборщика данных, идея одинакова для активных, пассивных проверок, для траппер элементов данных и т.д., посколько меняется только формат данных и участник связи (либо сборщик данных ожидает соединение и данные, либо сборщик данных инициирует соединение и запрашивает данные). Сырые данные проверяются, конфигурация элемента данных извлекается из кэше конфигурации (в данные добавляются конфигурационные данные).
- Механизм IPC на основе сокета используется для передачи данных от сборщиков данных к менеджеру предобработки. К этому моменту времени сборщик данных продолжает сбор данных без ожидания ответа от менеджера предварительной обработки.
- Выполняется предобработка данных. Что включает в себя выполнение шагов предварительной обработки и обработку зависимых элементов данных.
Элемент данных может изменить свое состояние на НЕПОДДЕРЖИВАЕТСЯ в процессе выполнения предобработки, если какой-либо шаг предобработки завершится с ошибкой.
- Данные истории из локального кэша данных менеджера предобработки сбрасываются в кэш истории.
- К этому моменту времени поток данных останвливается в ожидании следующей синхронизации кэша истории (когда процесс history syncer выполняет синхронизацию данных).
- Процесс синхронизации начинается с нормализации записываемых данных в базу данных Zabbix. Нормализация данных выполняет конвертации в желаемый тип элемента данных (тип заданный в конфигурации элемента данных), включая в себя обрезку текстовых данных на основе предопределенных размеров для этих типов (HISTORY_STR_VALUE_LEN для строк, HISTORY_TEXT_VALUE_LEN для текста и HISTORY_LOG_VALUE_LEN для журнал (лог) значений). Данные отправляются в базу данных Zabbix после завершения нормализации.
Элемент данных может изменить своё состояние на НЕПОДДЕРЖИВАЕТСЯ, если процесс нормализации завершится с ошибкой (например, когда текстовое значение не удалось сконвертировать в число).
- Выполняется обработка собранных данных - проверяются триггеры, обновляется конфигурация элементов данных, если элемент данных становится НЕПОДДЕРЖИВАЕМЫМ и тому подобное.
- Этот момент считается завершением потока данных с точки зрения обработки значений элементов данных.
Предварительная обработка значений элементов данных
Для визуализации процесса предобработки данных мы можем использовать следующую упрощенную диаграмму:
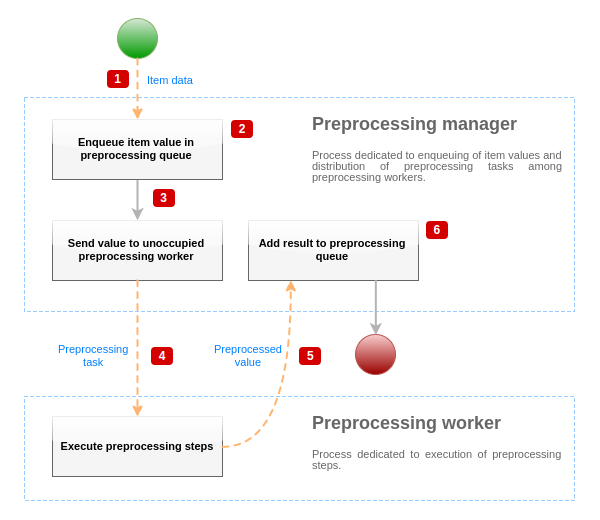
Диаграмма выше показывает только процессы, объекты и основные действия, которые связаны с предварительной обработкой значений элементов данных, в упрощенной форме. Диаграма не отображает изменения направлений при различных условиях, обработку ошибок или циклы. На диаграмме отображён только один "worker" предварительной обработки (в реальных сценариях могут использоваться несколько "workers" предобработки), обрабатывается только одно значение элемента днных и мы предполагаем, что этот элемент данных требует выполнения по крайней мере одного шага предварительной обработки. Цель этой диаграммы состоит в том, чтобы показать идею ниже потока предварительной обработки значения элемента данных.
- Данные элемента данных и значение элемента данных передаются менеджеру предобработки с использованием механизма IPC на основе сокета.
- Элемент данных помещается в очередь предобработки.
Элементы данных могут помещаться в конец и начало очереди предобработки. Элементы данных Zabbix внутренние всегда помещаются в начало очереди предобработки, тогда как другие элементы данных помещаются в конец.
- На данный момент времени поток данных останавливается пока появится по крайней мере один не занятый (тот, который не выполняет никакие задачи) "worker" предварительной обработки.
- Когда "worker" становится доступным, ему направляется задача предобработки.
- После заверщения предварительной обработки (как неудачно, так и успешно выполненные шаги предобработки), обработанное значение посылается обратно менеджеру предобработки.
- Менеджер предварительной обработки конвенртирует результат в желаемый формат (определяемый типом значения элемента данных) и помещает результат в очередь предварительной обработки. Если для текущего элемента данных имеются зависимые элементы данных, тогда зависимые элементы данных также добавляются в очередь предобработки. Зависимые элементы данных помещаются в очередь предобработки сразу после основного элемента данных, но только по тем основным элементам данных у которых имеется значение и они не находятся в НЕПОДДЕРЖИВАЕМОМ состоянии.
Поток обработки значения
Предварительная обработка значения элемента данных выполняется в несколько шагов (или фаз) несколькими процессами. Что может привести к:
- Зависимый элемент данных может принимать значения, когда основной элемент нет. Такое может произойти в случае следующего прецедента:
* У основного элемента данных тип значения ''UINT'', (можно использовать элемент данных траппер), у зависимого элемента данных тип значения ''TEXT''.
* Шаги предобработки не требуются как для основного, так и для зависимых элементов данных.
* Основному элементу данных необходимо передать текстовое значение (такое как, "abc").
* Так как выполняемые шаги предобработки отсутствуют, менеджер предобработки проверяет находится ли основной элемент данных в НЕПОДДЕРЖИВАЕМОМ состоянии и задано ли значение (оба условия правдивы) и помещает зависимый элемент данных в очередь с таким же значением, что и основной элемент данных (так как шаги предобработки отсутствуют).
* Когда элементы данных основной и зависимый переходят в фазу синхронизации истории, основной элемент данных становится НЕПОДДЕРЖИВАЕМЫМ, из-за ошибки конвертации значения (текстовые данные невозможно сконвертировать в целое положительное число).В результате зависимый элемент данных получает значение, тогда как основной элемент данных меняет свое состояние на НЕПОДДЕРЖИВАЕТСЯ.
- Зависимый элемент данных получает значение, которое отсутствует в истории основного элемента данных. Случай очень похож на предыдущий, за исключением типа основного элемента данных. Например, если у основного элемента данных используется тип
CHAR, тогда значение основного элемента данных будет обрезано на стадии синхронизации истории, в то время как зависимые элементы данных получат свои значения с изначального (не обрезанного) значения основного элемента данных.
Очередь предобработки
Очередь предварительной обработки это FIFO структура данных, в которой хранятся значения в соответствии с порядком в которым эти значения получены менеджером предобработки. Существует несколько исключений логики FIFO:
- Внутренние элементы данных помещаются в начало очереди
- Зависимые элементы данных всегда помещаются в очередь после основного элемента данных
Для визуализации логики очереди предобработки мы можем использовать следующую диаграмму:
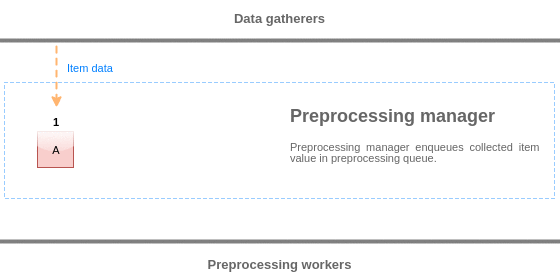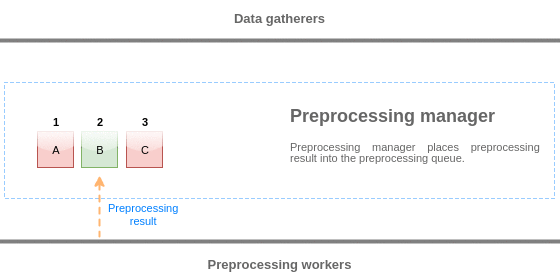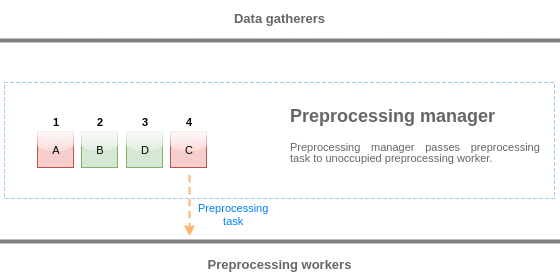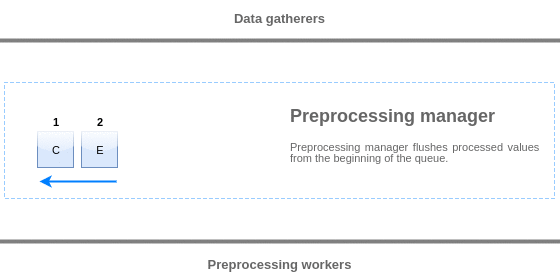
Значения из очереди предобработки сбрасываются начиная с начала очереди до первого необработанного значения. Таким образом, пример, менеджер предобработки сбросит значения 1, 2 и 3, но не сбросит значение 5, так как значение 4 ещё не обработано:

После сброса в очереди останутся только два значения (4 и 5), значения добавляются в локальный кэш данных менеджера предобработки и, затем значения перемещаются из локального кэша в кэш истории. Менеджер предвариетельной обработки может сбросить значения из локального кэша данных в режиме одного элемента данных или в массовом режиме (используется для зависимых элементов данных и значений, которые получены массово).
"Workers" предобработки
Файл конфигурации Zabbix сервера позволяет пользователям указать количество процессов "worker" предварительной обработки. Необходимо использовать параметр конфигурации StartPreprocessors, чтобы задать количество экземпляров пре-форков "workers" предобработки. Оптимальное количество "workers" предобработки может определяться многими факторами, включая количество "нуждающихся в предобработке" элементов данных (элементов данных, которые требуют выполнение любых шагов предварительной обработки), количество процессов сбора данных, среднее количество шагов при предобработке и так далее.
Но, предполагая, что тяжелые операции предобработки отсутствуют, такие как разбор больших кусков XML / JSON, количество "worker" предобработки может совпадать с количеством сборщиков данных. Таким образом, будет по крайней мере один незанятый "worker" предобработки (за исключением случаев, когда данные от сборщиков поступают массово) для собранных данных.
Слишком большое количество процессов сбора данных (поллеры, поллеры недоступных устройств, HTTP поллеры, Java поллеры, пингеры, трапперы, прокси поллеры), а также IPMI менеджер, SNMP траппер и worker предварительной обработки, могут исчерпать ограничение количества файловых дескрипторов по отдельным процессам для менеджера предварительной обработки. Что заставит Zabbix сервер остановиться (обычно в течении короткого периода времени после запуска, но иногда может занять более длительное время). Файл конфигурации необходимо пересмотреть или лимит должен быть увеличен, чтобы избежать подобной ситуации.