

Table of Contents
6 日志文件监控
概述
Zabbix可以集中监控和分析 支持/不支持日志轮询的日志文件。
当日志文件包含某些字符串或字符串模式时,可以使用通知来警告用户。
要监控日志文件,前提:
- 主机上已运行Zabbix agent
- 设置日志监控项
被监控日志文件的大小限制取决于 大文件支持。
配置
验证代理参数
确保在 代理配置文件 中已设置:
- 'Hostname'参数与前端的主机名一致
- 'ServerActive'参数中的服务器被指定用于处理主动检查
监控项配置
配置一个日志 监控项
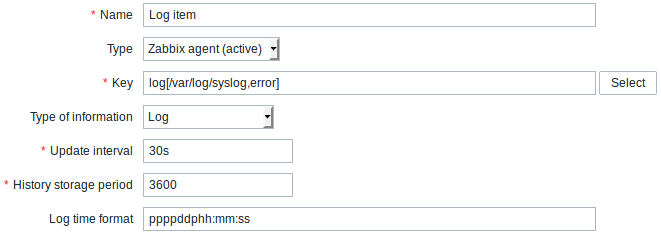
所有标有红色星号的为必填字段。
具体日志监控项的输入:
| Type | 这里选择 Zabbix agent (active) |
| Key | 设置: log[/path/to/file/file_name,<regexp>,<encoding>,<maxlines>,<mode>,<output>,<maxdelay>] or logrt[/path/to/file/regexp_describing_filename_pattern,<regexp>,<encoding>,<maxlines>,<mode>,<output>,<maxdelay>] Zabbix agent将通过内容正则表达式过(如果存在的话)滤日志文件的条目。 如果只需要匹配行的数量,设置: log.count[/path/to/file/file_name,<regexp>,<encoding>,<maxproclines>,<mode>,<maxdelay>] or logrt.count[/path/to/file/regexp_describing_filename_pattern,<regexp>,<encoding>,<maxproclines>,<mode>,<maxdelay>]. 确保zabbix用户具有文件的读写权限,否则监控项将被设置为“不支持”状态。 更多细节,请在 Zabbix agent监控项的键值章节中查看 log, log.count, logrt 和 logrt.count 的条目。 |
| Type of information | 在这里,log和logrt选择Log,log.count和logrt.count选择Numeric (unsigned). 如果可选使用 output参数,则可以选择除“日志”之外的适当类型的信息.注意,选择非日志类型的信息将导致本地时间戳的丢失. |
| Update interval (in sec) | 该参数定义了Zabbix代理检查日志文件中任何更改的频率。 将其设置为1秒将确保你能尽快的获得新记录。 |
| Log time format | 在此字段中,您可以选择指定解析日志行的时间戳的模式。 如果留空,则不会解析时间戳。 支持的占位符: * y: 年 (0001-9999) * M: 月 (01-12) * d: 日 (01-31) * h: 小时 (00-23) * m: 分 (00-59) * s: 秒 (00-59) 例如, 从Zabbix agent日志文件中查看以下行: " 23480:20100328:154718.045 Zabbix agent started. Zabbix 1.8.2 (revision 11211)." 它以PID的六个字符位置开始,后面跟日期、时间和行的其余部分。 此行的日志时间格式为 "pppppp:yyyyMMdd:hhmmss"。 注意, “p”和“:”字符只是占位符,而且只能是“yMdhms” |
注意事项
* 服务器和代理将监视日志的大小和最后修改时间(对于logrt)的跟踪保存在两个计数器中. 此外:
*代理还在内部使用inode编号(在UNIX/GNU/Linux上)、文件索引(在Microsoft Windows上)和前512个日志文件字节的MD5的求和,以便在日志文件被截断和旋转时改进决策。
* 在UNIX/GNU/Linux系统中,假定日志文件存储的文件系统是报告inode号,可以用来跟踪文件。
* 在Microsoft Windows系统上,Zabbix agent确定日志文件所在的文件系统类型,并使用:
* 在NTFS文件系统上64位文件索引。
* 在ReFS文件系统上 (仅从Microsoft Windows Server 2012开始支持)128位文件ID。
* 在文件索引发生变化(例如FAT32、exFAT)的文件系统中,当日志文件旋转导致多个日志文件在相同的最后修改时间内出现时,使用回退算法在不确定的条件下采取合理的方法。
* inode号,文件索引和MD5总和由Zabbix代理在内部收集。 它们不传输到Zabbix服务器,并且在Zabbix代理停止时丢失。
* 不要使用“touch”程序修改日志文件的最后修改时间,不要在以后恢复原始名称的情况下复制日志文件(这将更改文件inode号)。 在这两种情况下,文件将被视为不同的,将从头开始进行分析,这可能会导致重复的告警。
*如果logrt[]监控项有几个匹配的日志文件,并且Zabbix agent跟随其中最新的日志文件,并删除了最近的日志文件,则在“<目录>”中会出现一条警告消息“没有文件匹配”<regexp mask>“。 Zabbix代理将忽略修改时间小于最近日期的日志文件。
* 代理从上次停止的点开始读取日志文件。
* 在代理刚刚启动或已收到以前被禁用或不支持的监控项的情况下,已经分析的字节数(大小计数器)和最后修改时间(时间计数器)存储在Zabbix数据库中并发送到代理,以确保代理从此开始读取日志文件。但是,如果代理从服务器接受非零大小的计数器, 而logrt[] 和 logrt.count[] 监控项没有找到,也没找到匹配的文件,若文件稍后出现,大小计数器将重置为0,将从头开始分析。
* 每当日志文件变得小于代理已知的日志大小计数器时,计数器将重置为零,代理从开始位置读取日志文件,将时间计数器考虑在内。
* 如果目录中存在多个匹配文件,且最后修改时间相同,则代理会尝试以相同的修改时间对所有日志文件进行正确分析,并避免跳过数据或分析相同的数据两次(尽管有时不能保证)。代理不承担任何特定的日志文件轮换方案。当提供具有相同修改时间的多个日志文件时,代理将以字典顺序降序处理它们。 因此,对于某些旋转方案,日志文件将按原始顺序进行分析。对于其它旋转方案,原始日志文件顺序将不会被执行,这可能导致以更改顺序报告匹配的日志文件记录(如果日志文件的上次修改时间不同,则不会发生问题)。
* Zabbix agent每 //更新间隔// 秒处理一次日志文件的新记录。
* Zabbix agent不会每秒发送超过日志文件的 **最大值**。 该限制可防止网络和CPU资源的过载,并会覆盖 [[:manual:appendix:config:zabbix_agentd|代理配置文件]]中 **MaxLinesPerSecond** 参数提供的默认值。
* 要找到所需的字符串,Zabbix将处理比MaxLinesPerSecond中设置的多10倍的新行。例如,如果“log[]”或“logrt[]”监控项的 //更新间隔// 为1秒,那么在默认情况下,代理将分析不超过200条日志文件记录,并在一次检查中向Zabbix server发送不超过20条的匹配记录。通过在代理配置文件中增加**MaxLinesPerSecond**,或在监控项键中设置 **maxlines** 参数,一次检查可将分析日志文件记录和发送到Zabbix服务器的1000条匹配记录增加到10000条。如果 //更新间隔// 设置为2秒,那么一次检查的限制将被设置为高于//更新间隔// 1秒的2倍
* 此外,即使其中没有非日志值,日志和日志计数值始终限为代理发送缓冲区大小的50%。 因此,为了在一个连接(而不是几个连接)中发送最大值,代理的 [[:manual:appendix:config:zabbix_agentd|缓冲区大小]] 参数必须至少为maxlines x 2。
* 在没有日志项的情况下,所有代理缓冲区大小都用于非日志值。当日志值出现时,它们会根据需要替换旧的非日志值,最多可替换为指定的50%.
* 对于大于256kB的日志文件记录,只有前256kB与正则表达式匹配,而其余部分将被忽略。但是,如果Zabbix agent在处理长记录时停止,则会丢失代理的内部状态,并且在重新启动代理之后,可以对长记录进行不同的分析。
* 特别注意“\”路径分隔符: 如果file_format是"file\.log", 则不应该有“file”目录, 因为不可能明确地定义“.”是转义的还是文件名的第一个符号。
* 仅在文件名中支持“logrt”的正则表达式,不支持目录正则表达式匹配。
* 在UNIX平台上,如果要找的日志文件的目录不存在,则logrt[]监控项将变为NOTSUPPORTED。
* 在Microsoft Windows上,如果目录不存在,则监控项将不会变为NOTSUPPORTED(例如,目录在监控项键中拼写错误)。
* 没有用于logrt[]监控项的日志文件不会使其NOTSUPPORTED。读取logrt[]监控项的日志文件的错误将作为告警记录到Zabbix agent日志文件中,但不会使监控项变成NOTSUPPORTED。
* Zabbix agent日志文件可以帮助你找出为什么log[]或logrt[]监控项会成为NOTSUPPORTED。Zabbix可以监视其代理日志文件,除了在DebugLevel=4时。提取正则表达式的匹配部分
有时我们可能只想从目标文件中提取感兴趣的值,而不是在找到正则表达式匹配时返回整行。
自Zabbix 2.2.0以后,日志监控项能够从匹配的行中提取所需的值。这是在通过“log”和“logrt”监控项中附加 **output* 参数来实现的。
使用“output”参数可以指示我们可能感兴趣的匹配的子组。
例如
应该可以返回在以下内容中找到的条目数:
Fr Feb 07 2014 11:07:36.6690 */ Thread Id 1400 (GLEWF) large result
buffer allocation - /Length: 437136/Entries: 5948/Client Ver: >=10/RPC
ID: 41726453/User: AUser/Form: CFG:ServiceLevelAgreementZabbix只返回数字的原因是因为这里的'output'是由\1定义的,指的是第一个也是唯一的想要的子组:([0-9]+)
而且,通过提取和返回数字的能力,该值可用于定义触发器。
使用maxdelay参数
日志监控项中的“maxdelay”参数允许忽略日志文件中的一些较旧的行,以便在“maxdelay”秒内获取最近分析的行。
指定'maxdelay'>0可能导致 忽略重要的日志文件记录和错过的报警 ,只有在必要时才使用。
默认情况下,日志监控项将跟踪出现在日志文件中的所有新行。 但是,有些应用程序在某些情况下开始在其日志文件中写入大量的消息。例如,如果数据库或DNS服务器不可用,则此类应用程序会向日志文件中注入数千条几乎相同错误消息,直到恢复正常为止。默认情况下,所有这些消息将被完全分析,并将匹配的行发送到配置为“log”和“logrt”监控项的服务器上。
内置防过载保护包括一个可配置的“maxlines”参数(保护服务器免受太多传入匹配的日志行)和4*'maxlines限制(保护主机CPU和I/O免受代理在一次检查中过载)。不过,内置保护有两个问题。 首先,向服务器报告大量潜在的不太有用的消息,消耗数据库中的空间。 第二,由于每秒分析的行数有限,代理可能会滞后于最新的日志记录数小时。你可能希望尽快了解日志文件中的当前情况,而不是检查数小时的历史记录
这两个问题的解决方案都是是使用了'maxdelay'参数。 如果指定'maxdelay'> 0,在每次检查处理字节数时,将测量剩余字节数和处理时间。 代理根据这些数字,计算估计的延迟 - 分析日志文件中所有剩余记录所需的秒数。
如果延迟不超过“maxdelay”,那么代理将像往常一样继续分析日志文件。
如果延迟大于“maxdelay”,那么代理将通过“跳转”到一个新的估计位置来忽略日志文件的一个块,以便在“maxdelay”秒内分析剩下的行。
请注意,代理甚至不会将忽略的行读入缓冲区,而是计算要在文件中跳转的大致位置。
跳过日志文件行的事实记录在代理日志文件中,如下所示:
14287:20160602:174344.206 item:"logrt["/home/zabbix32/test[0-9].log",ERROR,,1000,,,120.0]"
logfile:"/home/zabbix32/test1.log" skipping 679858 bytes
(from byte 75653115 to byte 76332973) to meet maxdelay“to byte”数字是近似的,因为在“跳转”之后,代理将文件中的位置调整到日志行开头,日志行可能在文件中更远或更早。
根据增长速度与分析日志文件的速度的不同,你可能会看到没有"跳转"、少有或经常"跳转"、大或小的"跳转",甚至每次检查中的"跳转"都很小。系统负载和网络延迟的波动也会影响延迟的计算,因此"跳转"可以跟上“maxdelay”参数。
不推荐设置 'maxdelay' <'update interval'(这可能会导致频繁的"jumps")
处理“copytruncatetable”日志文件旋转的注意事项
带有“copytruncatetable”选项的“logrt”假定不同的日志文件有不同的记录(至少它们的时间戳不同),因此初始块的MD5(最多512字节)将不同。两个具有相同的MD5初始块和的文件意味着其中一个是原始块,另一个是副本。
使用“copytruncatetable”选项的“logrt”将努力正确处理日志文件副本,而不报告副本。但是,与logrt[]监控项更新间隔相比,生成具有相同时间戳的多个日志文件副本、日志文件旋转频率更高、不建议频繁重新启动代理。代理试图合理地处理所有这些情况,但是在所有情况下都不能保证良好的结果。
代理和服务器之间的通信失败时的操作
来自log[]和logrt[]监控项的每个匹配行以及每个log.count[]和logrt.count[]监控项检查的结果都需要代理发送缓冲区中指定的50%区域中的空闲时隙。缓冲区元素定期发送到服务器(或代理服务器),缓冲区可以再次释放。
虽然代理发送缓冲区中的指定日志区域中有空闲时隙,并且代理和服务器(或代理服务器)之间的通信失败,但是日志监控结果在发送缓冲区中累积。这有助于缓解短暂的通信故障。
在较长的通信失败期间,所有日志槽都被占用,并采取以下操作:
- “log[]”和“logrt[]”监控项检查已停止。当通信恢复并且缓冲器中的空闲插槽可用时,从先前的位置恢复检查。若没有匹配的行丢失,稍后再报告.
- 如果maxdelay=0(默认),则log.count[]和logrt.count[]监控被停止。 这种行为类似于上述的log[]和logrt[]监控项。 请注意,这可能会影响log.count[]和logrt.count[]结果:例如,一次检查计算出日志文件中有100个匹配行,但是由于缓冲区中没有空闲插槽,因此停止检查。 当通信恢复时,代理将计数相同的100条匹配行,还有70条新的匹配行。代理会发送count=170,就像它们在一次检查中发现的一样。
- log.count[]和logrt.count[]检查与maxdelay>0:如果在检查期间没有“跳转”,则行为类似于上述。 如果在日志文件行上发生“跳转”,则保留“跳转”之后的位置,同时计算结果被丢弃。 因此,即使在通信失败的情况下,代理也试图跟上日志文件的增长速度。