Documentation
Table of Contents
1 Alta disponibilitat
Vista general
L'alta disponibilitat (HA) es demana generalment a les infraestructures crítiques que no poden permetre's cap temps d'aturada. Per qualsevol servei susceptible de fallar, una opció de balanceig cap a un altre lloc és útil per evitar una aturada.
Zabbix propoa una solució d'alta disponibilitat nadiua fàcil de configurar i sense necessitat de cap experiència prèvia en HA. Zabbix HA nadiu és útil per una capa de protecció contra errades de programari/maquinari del servidor Zabbix o per tindre menys temps d'aturada per manteniments.
En mode alta disponibilitat de Zabbix, múltiples servidors executen com a nodes dins un clúster. Mentre un servidor Zabbix és actiu, els altres romanen a l'espera a punt de prendre el relleu si escau.
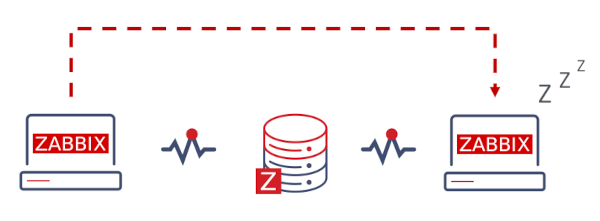
Encara que passem a Zabbix HA, sempre es pot fer marxa enrere en tot moment.
Veieu també: Detalls de la implementació
Activació de l'alta disponibilitat
Engegada del servidor Zabbix com a node d'un clúster
Es requereixen dos paràmetres a la configuració del servidor per iniciar un servidor Zabbix com a node de clúster:
- El paràmetre HANodeName s'ha d'especificar per a cada servidor Zabbix que serà un node de clúster HA.
Aquest és un identificador de node únic (per exemple, zabbix-node-01) al qual es farà referència al servidor en configuracions d'agent i proxy. Si no especifiqueu HANodeName, el servidor s'iniciarà en mode autònom.
- El paràmetre NodeAddress s'ha d'especificar per a cada node.
El paràmetre NodeAddress (adreça:port) serà emprat per la interfície Zabbix per connectar-se al node del servidor actiu. NodeAddress ha de coincidir amb el nom IP o FQDN del servidor Zabbix respectiu.
Reinicieu tots els servidors Zabbix després de fer canvis als fitxers de configuració. Ara s'iniciaran com a nodes de clúster. L'estat dels nous servidors es pot veure a Informes → Informació del sistema i també executant:
zabbix_server -R ha_statusAquesta ordre d'execució desarà l'estat actual del clúster HA al registre del servidor Zabbix (i a stdout):

Preparant la interfície
Assegureu-vos que l'adreça:port del servidor Zabbix sigui no definida a la configuració de la interfície (situada a `conf/zabbix.conf.php' del directori de fitxers de la interfície).

La interfície Zabbix detectarà automàticament el node actiu llegint els paràmetres de la taula de nodes a la base de dades Zabbix. L'adreça del node actiu s'emprarà com a adreça del servidor Zabbix.
Configuració del proxy
Els nodes de clúster HA (servidors) s'han d'enumerar a la configuració passiva o activa de proxy Zabbix.
Per a un proxy passiu, els noms dels nodes s'han d'enumerar al paràmetre del proxy, separats per una coma.
Servidor=zabbix-node-01,zabbix-node-02Per a un proxy actiu, els noms dels nodes haurien d'ésser llistats al paràmetre del proxy, separats per un punt i coma.
Servidor=zabbix-node-01;zabbix-node-02Configuració de l'agent
Els nodes de clúster HA (servidors) s'han d'enumerar a la configuració de l'agent Zabbix o de l'agent Zabbix 2.
Per activar les comprovacions passives, els noms dels nodes han d'ésser llistats al paràmetre del servidor, separats per una coma.
Servidor=zabbix-node-01,zabbix-node-02Per activar les comprovacions actives, els noms dels nodes han d'ésser llistats al paràmetre ServerActive. Tingueu en compte que per a les comprovacions actives, els nodes s'han de separar per comes de qualsevol altre servidor, mentre que els nodes s'han de separar amb un punt i coma, per exemple:
ActiveServer=zabbix-node-01;zabbix-node-02Failover cap a mode repòs
Zabbix passarà automàticament per error a un altre node si el node actiu cau. Hi ha d'haver almenys un node en estat d'espera perquè es produeixi la migració per error.
Amb quina rapidesa es produirà el failover? Tots els nodes actualitzen el seu darrer temps d'accés (i estat, si es canvia) cada 5 segons. Per tant:
Si el node actiu s'atura i aconsegueix informar del seu estat com a "aturat", un altre node prendrà el control en 5 segons.
Si el node actiu s'atura/és indisponible sense poder actualitzar el seu estat, els nodes en espera esperaran a endarreriment per error + 5 segons a prendre el control.
L'endarreriment de la migració per error és configurable, amb un interval compatible de 10 segons a 15 minuts (un minut per defecte). Per canviar l'endarreriment de la migració per error, podeu executar:
zabbix_server -R ha_set_failover_delay=5mGetió del cluster d'alta disponibilitat (HA)
L'estat actual del clúster HA es pot gestionar mitjançant les opcions dedicades control en temps d'execució:
ha_status: desa l'estat del clúster HA al registre del servidor Zabbix (i a stdout)ha_remove_node=target- elimina un node HA identificat pel seu <target> - nom o ID del node (nom/ID es poden obtindre a partir de la sortida de l'execució de ha_status), per exemple:
zabbix_server -R ha_remove_node=zabbix-node-02Tingueu en compte que els nodes actius/en espera no es poden pas esborrar.
ha_set_failover_delay=delay: estableix l'endarreriment de la migració per error HA (entre 10 segons i 15 minuts; s'admeten sufixos de temps, per exemple, 10 s, 1 m)
L'estat del node es pot controlar:
- a Informes → Informació del sistema
- al giny del tauler Informació del sistema
- emprant l'opció de control d'execució
ha_statusdel servidor (veieu més amunt).
L'element intern zabbix[cluster,discovery,nodes] es pot emprar per a la descoberta de nodes, ja que retorna un JSON amb informació de nodes d'alta disponibilitat.
Desactivació de l'alta disponibilitat
Per desactivar un clúster d'alta disponibilitat:
- teu còpies de seguretat dels fitxers de configuració
- tanqueu els nodes de còpia de seguretat
- esborreu el paràmetre HANodeName del servidor principal actiu
- reinicieu el servidor principal (iniciarà en mode autònom)
Detalla de la implementació
El clúster d'alta disponibilitat (HA) és una solució activada i és compatible amb el servidor Zabbix. La solució nadiua HA és dissenyada per ser senzilla d'emprar, funcionarà en tots els llocs i no té requisits específics per a les bases de dades reconegudes per Zabbix. Els usuaris poden emprar la solució nadiua de Zabbix HA o una solució de tercers, la que s'adapti millor als requisits d'alta disponibilitat del seu entorn.
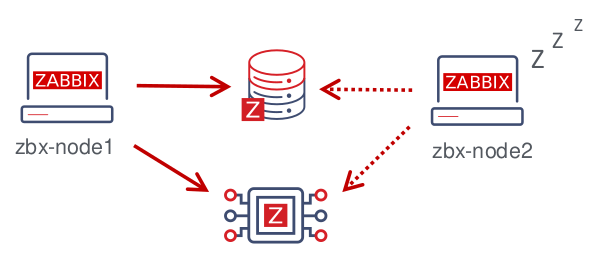
La solució consta de múltiples instàncies o nodes zabbix_server. Cada node: - es configura per separat - empra la mateixa base de dades - pot tindre diversos modes: actiu, en espera, no disponible, aturat
Només un node pot ésser actiu alhora. Un node d'espera només executa un procés: el gestor d'HA. Un node en espera no fa la recollida de dades, el processament ni altres activitats normals del servidor, ni escolta els ports; té connexions de base de dades mínimes.
Els nodes actius i en espera actualitzen el seu darrer temps d'accés cada 5 segons. Cada node d'espera monitora el darrer moment d'accés del node actiu. Si el darrer moment d'accés del node actiu és superior als segons de "temps d'espera de commutació per error", el node en espera es converteix en el node actiu i assigna l'estat "no disponible" al node anteriorment actiu.
El node actiu controla la seva pròpia connectivitat a la base de dades: si es perd durant més de delay de failover-5 segons, hauria d'aturar tot el processament i passar al mode d'espera. El node actiu també monitora l'estat dels nodes en espera: si el darrer temps d'accés d'un node en espera supera els segons de "temps d'espera per a errors", al node en espera se li assigna l'estat "no disponible".
Els nodes són dissenyats per ésser compatibles amb versions menors de Zabbix.