
-#5 通知升级
5 Escalations
概述
Overview
通过Escalations,您可以创建发送通知或执行远程命令的自定义场景。
With escalations you can create custom scenarios for sending notifications or executing remote commands.
实际应用中,这意味着:
In practical terms it means that:
- 用户可以立即收到新问题通知
- 通知可以重复,直到问题解决
- 发送通知可以延时
- 通知可以升级到另一个“较高”的用户组
- 可以立即执行远程命令,或者长时间不解决问题
<!-- -->- Users can be informed about new problems immediately
- Notifications can be repeated until the problem is resolved
- Sending a notification can be delayed
- Notifications can be escalated to another "higher" user group
- Remote commands can be executed immediately or when a problem is not resolved for a lengthy period
操作会根据升级步骤进行通知升级。 每一步都有一段时间。
Actions are escalated based on the escalation step. Each step has a duration in time.
您可以定义默认持续时间和单个步骤的自定义持续时间。一个升级步骤的最短持续时间为60秒。
You can define both the default duration and a custom duration of an individual step. The minimum duration of one escalation step is 60 seconds.
您可以从任何步骤开始执行操作,例如发送通知或执行命令。 第一步是立即采取行动。 如果要延迟操作,可以将其分配给稍后的步骤。 对于每个步骤,可以定义几个操作。
You can start actions, such as sending notifications or executing commands, from any step. Step one is for immediate actions. If you want to delay an action, you can assign it to a later step. For each step, several actions can be defined.
通知升级步骤的数量不受限制。
The number of escalation steps is not limited.
配置操作是即可定义Escalations. Escalations仅对问题操作支持,而不是恢复。
Escalations are defined when configuring an operation. Escalations are supported for problem operations only, not recovery.
Escalations的其他方面
Miscellaneous aspects of escalation behaviour
让我们考虑如果一个操作包含几个升级步骤,在不同的情况下会发生什么。
Let's consider what happens in different circumstances if an action contains several escalation steps.
| 情况 运 | |
|---|---|
| 在发送初始问题通知后,所涉及的主机进入维护状态 取决于action[配置](/manual/ | onfig/notifications/action/operation#configuring_an_operation)中设置的在维护期间暂停操作 , 所有剩余的升级步骤都由维护期间或延迟引起的延迟执行. 维护期不能取消操作. |
| 在时间段操作条件中定义的时间段在发送初始通知后结束 执行所有剩余的升级步骤. 时间段 条件不能停 | 操作; 它对于何时启动/未启动操作而不是操作具有效果。 |
| 维护过程中出现问题,维护结束后继续(未解决) 取决于action[配置](/manual | config/notifications/action/operation#configuring_an_operation)中在维护期间暂停操作 的设置,所有升级步骤都可以从维护结束或立即执行. |
| 在无数据维护期间会出现问题,并在维护结束后继续(未解决) 在执行所有升级步骤之前,必须等待触发器触发. | |
| 不同的升级紧随其后并重叠 每个新的升级的执行取代 | 前的升级,但是至少一个升级步骤总是在以前的升级中执行. 在针对触发器的每个事件评估创建的事件的操作中,此行为都是相关的. |
| 在升级过程中(如正在发送的消息),基于任何类型的事件:\ 发送正在发送的消息,然后再发送一条关于升级的消息.后- 该操作被禁用 - 该事件被删除 基于触发事件: - 触发器被禁用或删除 - 主机或项目被禁用 基于关于触发器的内部事件: - 触发器被禁用或删除 基于关于项目/低级发现规则的内部事件: - 该项目被禁用或删除 - 主机被禁用 |
消息将在邮件正文的开头有取消文本(注意:取消邮件已取消) 命名原因(例如,注意:取消升级:动作'<动作名称>'禁用).通过这种方式,收件人被通知升级被取消,不再执行任何步骤。 此消息将发送给接收通知的所有人员. 取消的原因也记录到服务器日志文件中(从Debug Level 3=Warning)开始. |
| 在升级过程中(如发送消息),删除该操作 不再发送消息. 信息被记录到服务器日 | 文件 (从Debug Level 3=Warning)开始, 例如: escalation cancelled: action id:334 deleted |
| Situation | Behaviour |
|---|---|
| The host in question goes into maintenance after the initial problem notification is sent | Depending on the Pause operations while in maintenance setting in action configuration, all remaining escalation steps are executed either with a delay caused by the maintenance period or without delay. A maintenance period does not cancel operations. |
| The time period defined in the Time period action condition ends after the initial notification is sent | All remaining escalation steps are executed. The Time period condition cannot stop operations; it has effect with regard to when actions are started/not started, not operations. |
| A problem starts during maintenance and continues (is not resolved) after maintenance ends | Depending on the Pause operations while in maintenance setting in action configuration, all escalation steps are executed either from the moment maintenance ends or immediately. |
| A problem starts during a no-data maintenance and continues (is not resolved) after maintenance ends | It must wait for the trigger to fire, before all escalation steps are executed. |
| Different escalations follow in close succession and overlap | The execution of each new escalation supersedes the previous escalation, but for at least one escalation step that is always executed on the previous escalation. This behavior is relevant in actions upon events that are created with EVERY problem evaluation of the trigger. |
| During an escalation in progress (like a message being sent), based on any type of event: - the action is disabled - the event is deleted Based on trigger event: - the trigger is disabled or deleted - the host or item is disabled Based on internal event about triggers: - the trigger is disabled or deleted Based on internal event about items/low-level discovery rules: - the item is disabled or deleted - the host is disabled |
The message in progress is sent and then one more message on the escalation is sent. The follow-up message will have the cancellation text at the beginning of the message body (NOTE: Escalation cancelled) naming the reason (for example, NOTE: Escalation cancelled: action '<Action name>' disabled). This way the recipient is informed that the escalation is cancelled and no more steps will be executed. This message is sent to all who received the notifications before. The reason of cancellation is also logged to the server log file (starting from Debug Level 3=Warning). |
| During an escalation in progress (like a message being sent) the action is deleted | No more messages are sent. The information is logged to the server log file (starting from Debug Level 3=Warning), for example: escalation cancelled: action id:334 deleted |
Escalation 示例
Escalation examples
示例 e 1
Example 1
Sending a repeated notification once every 30 minutes (5 times in total) to a 'MySQL Administrators' group. To configure:
- in Operations tab, set the Default operation step duration to '1800' seconds (30 minutes)
- Set the escalation steps to be From '1' To '5'
- Select the 'MySQL Administrators' group as recipients of the message

Notifications will be sent at 0:00, 0:30, 1:00, 1:30, 2:00 hours after the problem starts (unless, of course, the problem is resolved sooner).
If the problem is resolved and a recovery message is configured, it will be sent to those who received at least one problem message within this escalation scenario.
If the trigger that generated an active escalation is disabled, Zabbix sends an informative message about it to all those that have already received notifications.
Sending a repeated notification once every 30 minutes (5 times in total) to a 'MySQL Administrators' group. To configure:
- in Operations tab, set the Default operation step duration to '30m' (30 minutes)
- Set the escalation steps to be From '1' To '5'
- Select the 'MySQL Administrators' group as recipients of the message
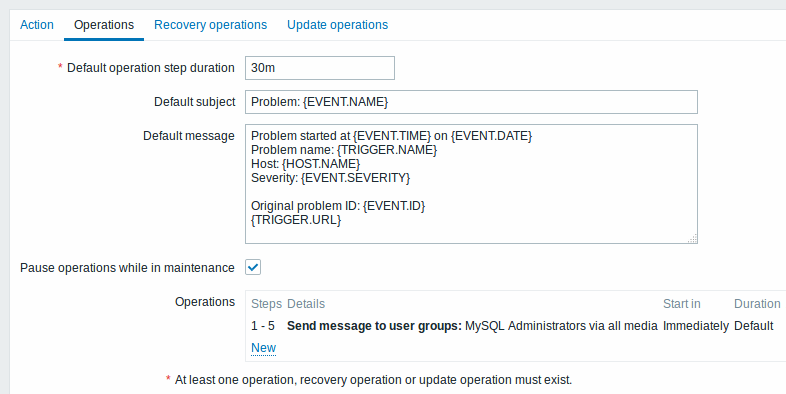
All mandatory input fields are marked with a red asterisk.
Notifications will be sent at 0:00, 0:30, 1:00, 1:30, 2:00 hours after the problem starts (unless, of course, the problem is resolved sooner).
If the problem is resolved and a recovery message is configured, it will be sent to those who received at least one problem message within this escalation scenario.
If the trigger that generated an active escalation is disabled, Zabbix sends an informative message about it to all those that have already received notifications.
示例 2
Sending a delayed notification about a long-standing problem. To configure:
- In Operations tab, set the Default operation step duration to '36000' seconds (10 hours)
- Set the escalation steps to be From '2' To '2'

A notification will only be sent at Step 2 of the escalation scenario, or 10 hours after the problem starts.
You can customize the message text to something like 'The problem is more than 10 hours old'.
Example 2
Sending a delayed notification about a long-standing problem. To configure:
- In Operations tab, set the Default operation step duration to '10h' seconds (10 hours)
- Set the escalation steps to be From '2' To '2'
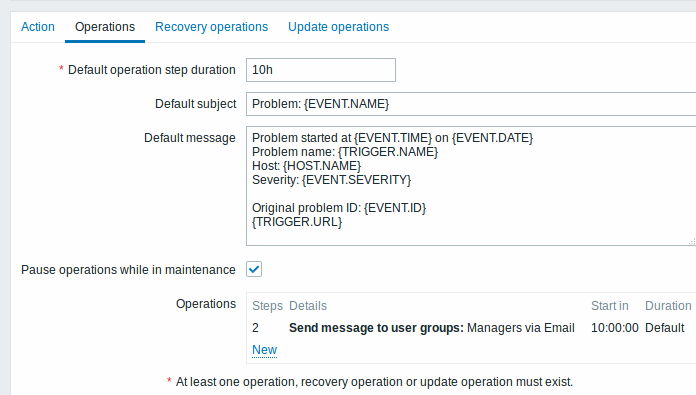
A notification will only be sent at Step 2 of the escalation scenario, or 10 hours after the problem starts.
You can customize the message text to something like 'The problem is more than 10 hours old'.
示例 3
Escalating the problem to the Boss.
In the first example above we configured periodical sending of messages to MySQL administrators. In this case, the administrators will get four messages before the problem will be escalated to the Database manager. Note that the manager will get a message only in case the problem is not acknowledged yet, supposedly no one is working on it.

Note the use of {ESC.HISTORY} macro in the message. The macro will contain information about all previously executed steps on this escalation, such as notifications sent and commands executed.
Example 3
Escalating the problem to the Boss.
In the first example above we configured periodical sending of messages to MySQL administrators. In this case, the administrators will get four messages before the problem will be escalated to the Database manager. Note that the manager will get a message only in case the problem is not acknowledged yet, supposedly no one is working on it.

Note the use of {ESC.HISTORY} macro in the message. The macro will contain information about all previously executed steps on this escalation, such as notifications sent and commands executed.
示例 4
A more complex scenario. After multiple messages to MySQL administrators and escalation to the manager, Zabbix will try to restart the MySQL database. It will happen if the problem exists for 2:30 hours and it hasn't been acknowledged.
If the problem still exists, after another 30 minutes Zabbix will send a message to all guest users.
If this does not help, after another hour Zabbix will reboot server with the MySQL database (second remote command) using IPMI commands.
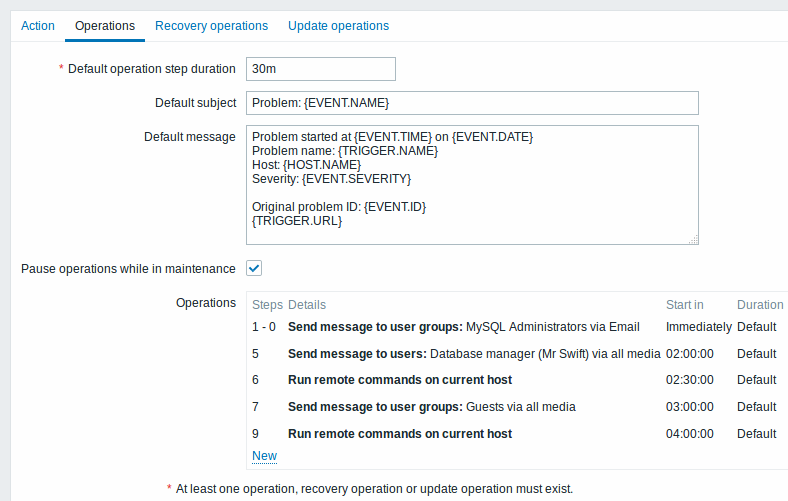
Example 4
A more complex scenario. After multiple messages to MySQL administrators and escalation to the manager, Zabbix will try to restart the MySQL database. It will happen if the problem exists for 2:30 hours and it hasn't been acknowledged.
If the problem still exists, after another 30 minutes Zabbix will send a message to all guest users.
If this does not help, after another hour Zabbix will reboot server with the MySQL database (second remote command) using IPMI commands.
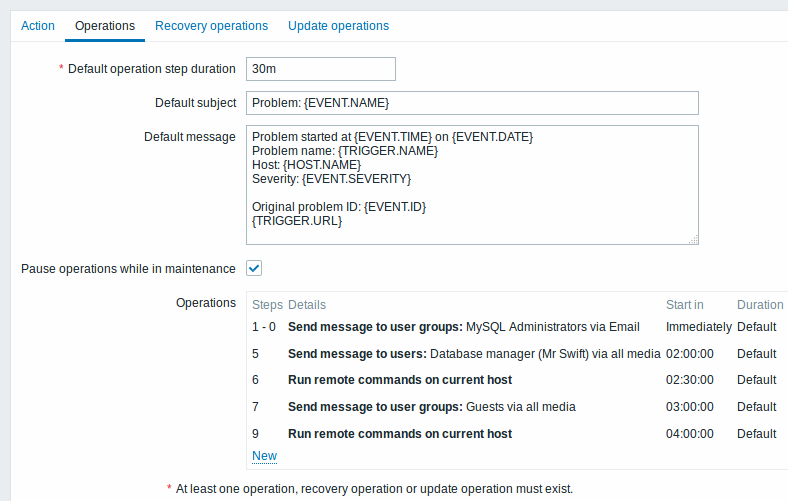
示例 5
An escalation with several operations assigned to one step and custom intervals used. The default operation step duration is 30 minutes.

Example 5
An escalation with several operations assigned to one step and custom intervals used. The default operation step duration is 30 minutes.
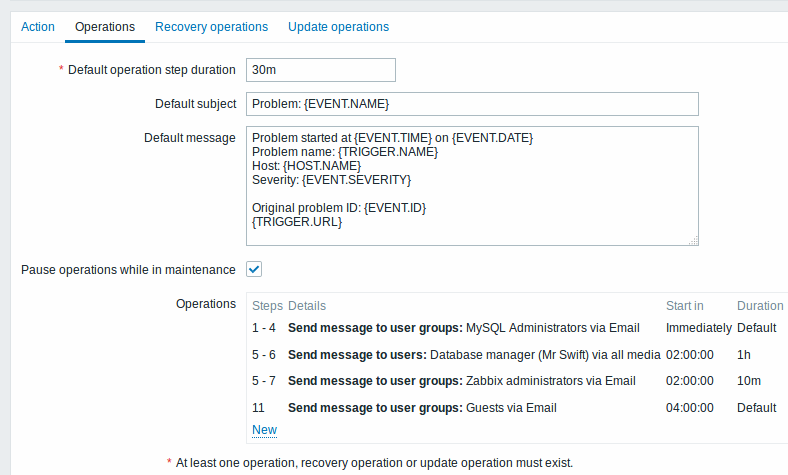
通知将发送如下:
Notifications will be sent as follows:
- to MySQL administrators at 0:00, 0:30, 1:00, 1:30 after the problem starts
- to Database manager at 2:00 and 2:10 (and not at 3:00; seeing that steps 5 and 6 overlap with the next operation, the shorter custom step duration of 600 seconds in the next operation overrides the longer step duration of 3600 seconds tried to set here)
- to Zabbix administrators at 2:00, 2:10, 2:20 after the problem starts (the custom step duration of 600 seconds working)
- to guest users at 4:00 hours after the problem start (the default step duration of 30 minutes returning between steps 8 and 11)
<!-- -->- to MySQL administrators at 0:00, 0:30, 1:00, 1:30 after the problem starts
- to Database manager at 2:00 and 2:10 (and not at 3:00; seeing that steps 5 and 6 overlap with the next operation, the shorter custom step duration of 10 minutes in the next operation overrides the longer step duration of 1 hour tried to set here)
- to Zabbix administrators at 2:00, 2:10, 2:20 after the problem starts (the custom step duration of 10 minutes working)
- to guest users at 4:00 hours after the problem start (the default step duration of 30 minutes returning between steps 8 and 11)