
12 Détails du prétraitement de la valeur de l'élément
Aperçu
Le pré-traitement des valeurs d’élément permet de définir et d’exécuter des règles de transformation pour les valeurs d’élément reçues.
Le pré-traitement est géré par un processus gestionnaire de pré-traitement, ajouté dans Zabbix 3.4, ainsi que par des agents de pré-traitement exécutant les étapes de pré-traitement. Toutes les valeurs (avec ou sans pré-traitement) de différents collecteurs de données transitent par le gestionnaire de pré-traitement avant d'être ajoutées au cache d'historique. La communication IPC basée sur les sockets est utilisée entre les collecteurs de données (pollers, trappers, etc.) et le processus de pré-traitement. Seul le serveur Zabbix exécute des étapes de pré-traitement.
Traitement de la valeur de l'élément
Pour visualiser le flux de données de la source de données à la base de données Zabbix, nous pouvons utiliser le diagramme simplifié suivant :
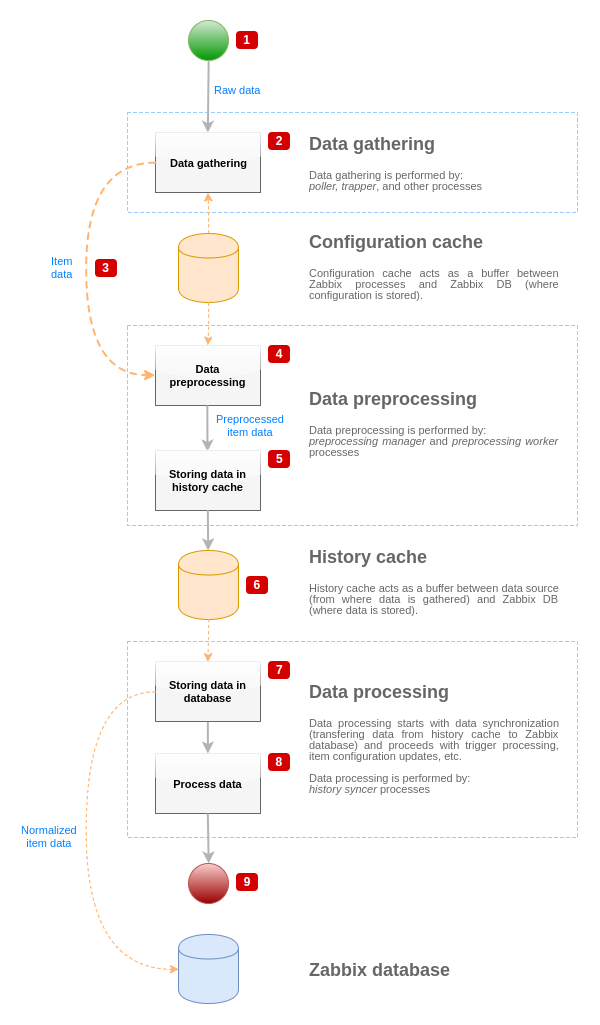
Le diagramme ci-dessus montre uniquement les processus, les objets et les actions liés au traitement de la valeur d'un élément sous une forme simplifiée. Le diagramme ne montre pas les changements de direction conditionnels, la gestion des erreurs ou les boucles. Le cache de données local du gestionnaire de pré-traitement ne s'affiche pas non plus, car il n'affecte pas directement le flux de données. Le but de ce diagramme est de montrer les processus impliqués dans le traitement des valeurs d’éléments et leur interaction.
- La collecte de données commence par les données brutes d'une source de données. À ce stade, les données ne contiennent que l'ID, l'horodatage et la valeur (peuvent également contenir plusieurs valeurs).
- Quel que soit le type de collecteur de données utilisé, l’idée est la même pour les vérifications actives ou passives, pour les éléments trappers, etc., dans la mesure où cela ne change que le format des données et l'initiation de la communication (le collecteur de données attend une connexion et des données, ou le collecteur de données initie la communication et demande les données). Les données brutes sont validées, la configuration des éléments est extraite du cache de configuration (les données sont enrichies avec les données de configuration).
- Le mécanisme IPC basé sur le socket est utilisé pour transférer les données des collecteurs de données au gestionnaire de pré-traitement. À ce stade, le collecteur de données continue de collecter des données sans attendre la réponse du gestionnaire de pré-traitement.
- Le pré-traitement des données est effectué. Cela inclut l'exécution des étapes de pré-traitement et du traitement des éléments dépendants.
L'élément peut changer son état en NON SUPPORTÉ lors du pré-traitement si l'une des étapes du pré-traitement échoue.
- Les données d'historique du cache de données local du gestionnaire de pré-traitement sont vidées dans le cache d'historique.
- À ce stade, le flux de données s'arrête jusqu'à la synchronisation suivante du cache d'historique (lorsque le processus synchronisation d'historique effectue la synchronisation des données).
- Le processus de synchronisation commence par la normalisation des données qui les stocke dans la base de données Zabbix. La normalisation des données effectue des conversions vers le type d'élément souhaité (type défini dans la configuration d'élément), y compris la troncature des données textuelles en fonction des tailles prédéfinies autorisées pour ces types (HISTORY_STR_VALUE_LEN pour la chaîne, HISTORY_TEXT_VALUE_LEN pour le texte et HISTORY_LOG_VALUE_LEN pour les valeurs de journal). Les données sont envoyées à la base de données Zabbix après la normalisation.
L'élément peut changer son état en NON SUPPORTÉ si la normalisation des données échoue (par exemple, lorsque la valeur textuelle ne peut pas être convertie en nombre).
- Les données collectées sont en cours de traitement - les déclencheurs sont vérifiés, la configuration de l'élément est mise à jour si l'élément devient NON SUPPORTÉ, etc.
- Ceci est considéré comme la fin du flux de données du point de vue du traitement de la valeur de l'élément.
Prétraitement de la valeur d'élément
Pour visualiser le processus de pré-traitement des données, nous pouvons utiliser le schéma simplifié suivant :
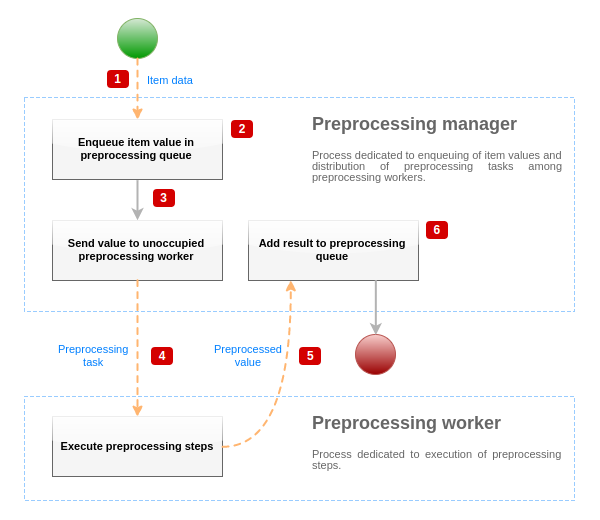
Le diagramme ci-dessus montre uniquement les processus, les objets et les actions principales liés au pré-traitement des valeurs d’élément sous une forme simplifiée. Le diagramme ne montre pas les changements de direction conditionnels, la gestion des erreurs ou les boucles. Ce diagramme ne présente qu'un seul agent de traitement (plusieurs agents de traitement peuvent être utilisés dans des scénarios réels), une seule valeur d'élément est en cours de traitement et nous supposons que cet élément nécessite l'exécution d'au moins une étape de pré-traitement. Le but de ce diagramme est de montrer l’idée derrière le pipeline de pré-traitement des valeurs d’élément.
- Les données et la valeur d'élément sont transmises au gestionnaire de pré-traitement à l'aide du mécanisme IPC basé sur le socket.
- L'élément est placé dans la file d'attente de pré-traitement.
L'élément peut être placé à la fin ou au début de la file d'attente de pré-traitement. Les éléments internes de Zabbix sont toujours placés au début de la file d'attente de pré-traitement, tandis que les autres types d'éléments sont mis en file d'attente à la fin.
- À ce stade, le flux de données s’arrête jusqu’à ce qu’il y ait au moins un worker de pré-traitement inoccupé (qui n’exécute aucune tâche).
- Lorsqu'un agent de pré-traitement est disponible, une tâche de pré-traitement lui est envoyée.
- Une fois le pré-traitement terminé (exécution réussie des étapes de pré-traitement), la valeur pré-traitée est renvoyée au gestionnaire de pré-traitement.
- Le gestionnaire de pré-traitement convertit le résultat au format souhaité (défini par le type de valeur de l’élément) et place les résultats en file d’attente de pré-traitement. S'il existe des éléments dépendants pour l'élément en cours, ceux-ci sont également ajoutés à la file d'attente de pré-traitement. Les éléments dépendants sont mis en file d'attente dans la file d'attente de pré-traitement juste après l'élément principal, mais uniquement pour les éléments principaux avec une valeur définie et non dans l'état NON SUPPORTÉ.
Pipeline de traitement de la valeur
Le traitement de la valeur d'élément est exécuté en plusieurs étapes (ou phases) par plusieurs processus. Cela peut causer :
- L'élément dépendant peut recevoir des valeurs, alors que LA valeur principale ne le peut pas. Ceci peut être réalisé en utilisant le cas d'utilisation suivant :
<!-- --> * L'élément principal a le type de valeur ''UINT'' (l'élément trapper peut être utilisé), l'élément dépendant a le type de valeur ''TEXT''.
* Aucune étape de pré-traitement n'est requise pour les éléments principaux et dépendants.
* La valeur textuelle (comme "abc") doit être transmise à l'élément principal.
* Comme il n’y a pas d’étapes de pré-traitement à exécuter, le gestionnaire de pré-traitement vérifie si l’élément principal n’est pas à l’état NON SUPPORTÉ et si la valeur est définie (les deux sont vrais) et place en file d'attente l’élément dépendant ayant la même valeur que l’élément principal (en l’absence d’étapes de pré-traitement).
* Lorsque les éléments principaux et dépendants atteignent tous les deux la phase de synchronisation d'historique, l'élément principal devient NON SUPPORTÉ, en raison de l'erreur de conversion de valeur (les données textuelles ne peuvent pas être converties en un entier non signé).Par conséquent, l'élément dépendant reçoit une valeur, tandis que l'élément principal change son état en NON SUPPORTÉ.
- L'élément dépendant reçoit une valeur qui n'est pas présente dans
l'historique de l'élément principal. Le cas d'utilisation est très
similaire au précédent, à l'exception du type de l'élément
principal. Par exemple, si le type
CHARest utilisé pour un élément principal, la valeur de cet élément sera tronquée à la phase de synchronisation d'historique, tandis que les éléments dépendants recevront leur valeur de la valeur initiale (non tronquée) de l'élément principal.
File d'attente de pré-traitement
La file d'attente de pré-traitement est une structure de données FIFO qui stocke les valeurs en préservant l'ordre dans lequel les valeurs sont visualisées par le gestionnaire de pré-traitement. Il y a plusieurs exceptions à la logique FIFO :
- Les éléments internes sont mis en file d'attente au début de la file d'attente.
- Les éléments dépendants sont toujours mis en file d'attente après l'élément principal
Pour visualiser la logique de la file d'attente de pré-traitement, nous pouvons utiliser le diagramme suivant :
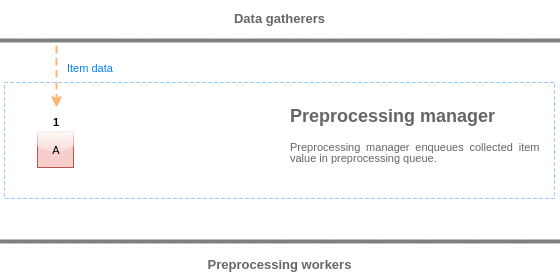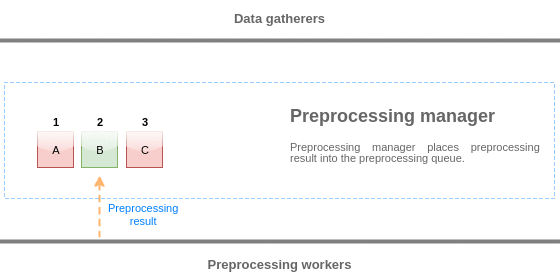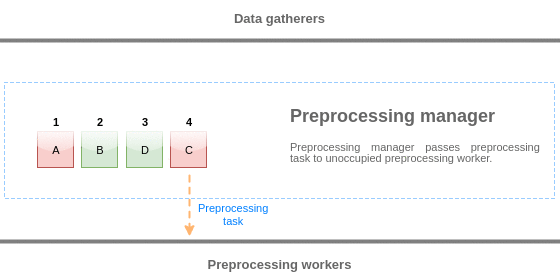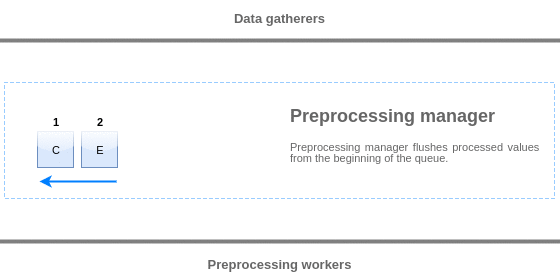
Les valeurs de la file d'attente de pré-traitement sont vidées du début à la première valeur non traitée. Ainsi, par exemple, le gestionnaire de pré-traitement supprime les valeurs 1, 2 et 3, mais pas la valeur 5 car la valeur 4 n'est pas encore traitée :

Seules deux valeurs sont laissées dans la file d'attente (4 et 5) après le vidage, les valeurs sont ajoutées dans le cache de données local du gestionnaire de pré-traitement, puis les valeurs sont transférées du cache local vers le cache d'historique. Le gestionnaire de pré-traitement peut vider les valeurs du cache de données local en mode élément unique ou en bloc (utilisé pour les éléments dépendants et les valeurs reçues en bloc).
Workers de prétraitement
Le fichier de configuration du serveur Zabbix permet aux utilisateurs de définir le nombre de processus worker de pré-traitement. Le paramètre de configuration StartPreprocessors doit être utilisé pour définir le nombre d'instances prédéfinies de workers de pré-traitement. De nombreux facteurs peuvent déterminer le nombre optimal de workers de pré-traitement, notamment le nombre d'éléments "préprocessables" (éléments nécessitant l'exécution d'une étape de pré-traitement), le nombre de processus de collecte de données, le nombre moyen d'étapes pour le pré-traitement d'éléments, etc.
Mais en supposant qu'il n'y ait pas d'opérations de pré-traitement lourdes comme l'analyse de gros morceaux XML/JSON, le nombre de workers de pré-traitement peut correspondre au nombre total de collecteurs de données. De cette manière, il y aura principalement (sauf dans les cas où les données du collecteur seront fournies en masse) au moins un worker de pré-traitement inoccupé pour les données collectées.
Trop de processus de collecte de données (pollers, pollers d'inaccessibilité, pollers HTTP, pollers Java, pingers, pingers, pollers proxy) associés au gestionnaire IPMI, au trapper SNMP et aux workers de pré-traitement peuvent dépasser la limite du descripteur de fichier par processus du gestionnaire de pré-traitement. Cela provoquera l'arrêt du serveur Zabbix (généralement peu de temps après le démarrage, mais cela peut parfois prendre plus de temps). Le fichier de configuration doit être révisé ou la limite doit être augmentée pour éviter cette situation.