Documentation
Table of Contents
2 Voorverwerkingsdetails
Overzicht
Dit gedeelte biedt details over de voorverwerking van itemwaarden. De voorverwerking van itemwaarden maakt het mogelijk om transformatieregels voor de ontvangen itemwaarden te definiëren en uit te voeren.
De voorverwerking wordt beheerd door het voorverwerkingsbeheerproces, samen met voorverwerkingswerkers die de voorverwerkingsstappen uitvoeren. Alle waarden (met of zonder voorverwerking) van verschillende gegevensverzamelaars gaan door het voorverwerkingsbeheer voordat ze aan de geschiedeniscache worden toegevoegd. Er wordt gebruik gemaakt van socketgebaseerde IPC-communicatie tussen gegevensverzamelaars (pollers, trappers, enz.) en het voorverwerkingsproces. Zowel de Zabbix-server als de Zabbix-proxy (voor items die worden bewaakt door de proxy) voeren voorverwerkingsstappen uit.
Verwerking van itemwaarden
Om de gegevensstroom van de gegevensbron naar de Zabbix-database te visualiseren, kunnen we de volgende vereenvoudigde diagram gebruiken:
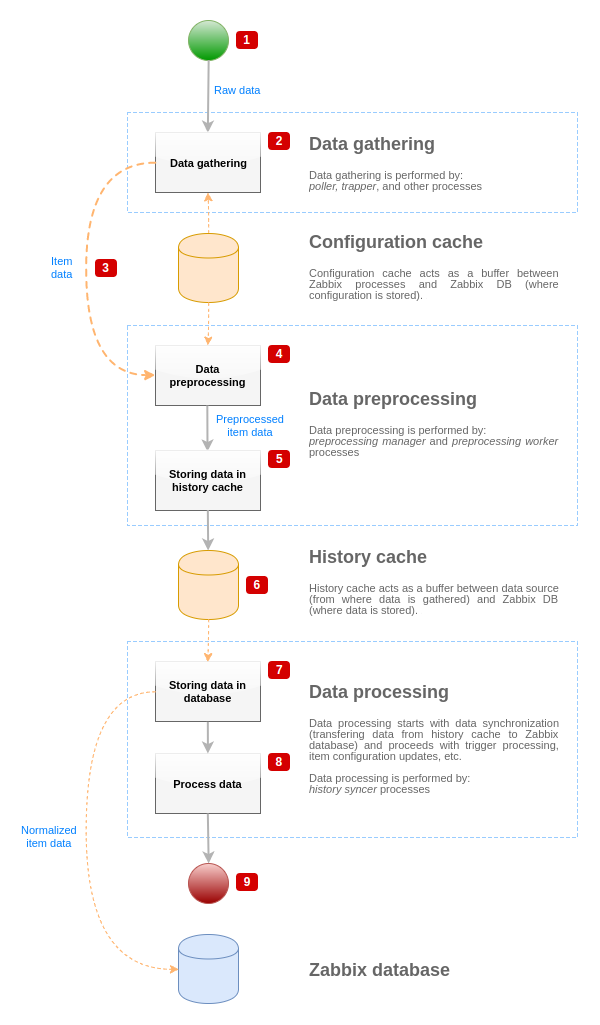
Het bovenstaande diagram toont alleen processen, objecten en acties die verband houden met de verwerking van itemwaarden in een vereenvoudigde vorm. Het diagram toont geen voorwaardelijke richtingswijzigingen, foutafhandeling of lussen. De lokale gegevenscache van het voorverwerkingsbeheer wordt ook niet weergegeven omdat dit de gegevensstroom niet direct beïnvloedt. Het doel van dit diagram is om de processen te laten zien die betrokken zijn bij de verwerking van itemwaarden en de manier waarop ze met elkaar communiceren.
- Gegevensverzameling begint met ruwe gegevens van een gegevensbron. Op dit punt bevatten de gegevens alleen ID, tijdstempel en waarde (het kunnen ook meerdere waarden zijn).
- Ongeacht het type gegevensverzamelaar dat wordt gebruikt, is het idee hetzelfde voor actieve of passieve controles, voor trapper-items, enzovoort, omdat alleen het gegevensformaat en de communicatie-initiator veranderen (ofwel de gegevensverzamelaar wacht op een verbinding en gegevens, of de gegevensverzamelaar initieert de communicatie en vraagt om de gegevens). De ruwe gegevens worden gevalideerd, de itemconfiguratie wordt opgehaald uit de configuratiecache (de gegevens worden verrijkt met de configuratiegegevens).
- Er wordt een socketgebaseerd IPC-mechanisme gebruikt om gegevens van gegevensverzamelaars naar het voorverwerkingsbeheer door te geven. Op dit punt gaat de gegevensverzamelaar door met het verzamelen van gegevens zonder te wachten op de respons van het voorverwerkingsbeheer.
- Gegevensvoorverwerking wordt uitgevoerd. Dit omvat het uitvoeren van voorverwerkingsstappen en afhankelijke verwerking van items.
Een item kan tijdens het uitvoeren van voorverwerking van status veranderen naar NIET ONDERSTEUND als een van de voorverwerkingsstappen mislukt.
- De geschiedenisgegevens uit de lokale gegevenscache van het voorverwerkingsbeheer worden in de geschiedeniscache geleegd.
- Op dit punt stopt de gegevensstroom tot de volgende synchronisatie van de geschiedeniscache (wanneer het geschiedenissynchronisatieproces gegevenssynchronisatie uitvoert).
- Het synchronisatieproces begint met gegevensnormalisatie voordat de gegevens in de Zabbix-database worden opgeslagen. De gegevensnormalisatie voert conversies uit naar het gewenste itemtype (type gedefinieerd in de itemconfiguratie), inclusief het inkorten van tekstuele gegevens op basis van vooraf gedefinieerde groottes die zijn toegestaan voor die typen (HISTORY_STR_VALUE_LEN voor string, HISTORY_TEXT_VALUE_LEN voor tekst en HISTORY_LOG_VALUE_LEN voor logwaarden). De gegevens worden naar de Zabbix-database gestuurd nadat de normalisatie is voltooid.
Een item kan van status veranderen naar NIET ONDERSTEUND als de normalisatie van gegevens mislukt (bijvoorbeeld wanneer een tekstuele waarde niet kan worden omgezet naar een getal).
- De verzamelde gegevens worden verwerkt - triggers worden gecontroleerd, de itemconfiguratie wordt bijgewerkt als het item NIET ONDERSTEUND wordt, enzovoort.
- Dit wordt beschouwd als het einde van de gegevensstroom vanuit het oogpunt van de verwerking van itemwaarden.
Voorverwerking van itemwaarden
Gegevensvoorverwerking wordt uitgevoerd in de volgende stappen:
- De itemwaarde wordt naar het voorverwerkingsbeheer doorgegeven via een IPC-mechanisme op basis van UNIX-sockets.
- Als het item noch voorverwerking noch afhankelijke items heeft, wordt de waarde ervan toegevoegd aan de geschiedeniscache of naar het LLD-beheer gestuurd. Anders:
- Er wordt een voorverwerkingsopdracht gemaakt en aan de wachtrij toegevoegd, en voorverwerkingswerkers worden op de hoogte gebracht van de nieuwe taak.
- Op dit punt stopt de gegevensstroom totdat er ten minste één niet-bezette (d.w.z. geen enkele taak uitvoerende) voorverwerkingswerker beschikbaar is.
- Wanneer er een voorverwerkingswerker beschikbaar is, neemt deze de volgende taak uit de wachtrij.
- Nadat de voorverwerking is voltooid (zowel mislukte als succesvolle uitvoering van voorverwerkingsstappen), wordt de voorverwerkte waarde toegevoegd aan de wachtrij met voltooide taken en wordt het beheer op de hoogte gebracht van een nieuwe voltooide taak.
- Het voorverwerkingsbeheer converteert het resultaat naar het gewenste formaat (gedefinieerd door het type itemwaarde) en voegt het toe aan de geschiedeniscache of stuurt het naar het LLD-beheer.
- Als er afhankelijke items zijn voor het verwerkte item, worden afhankelijke items aan de voorverwerkingswachtrij toegevoegd met de voorverwerkte waarde van het hoofditem. Afhankelijke items worden in de wachtrij gezet door normale verzoeken voor waardevoorverwerking over te slaan, maar alleen voor hoofditems met de waarde ingesteld en niet in de status NIET ONDERSTEUND.
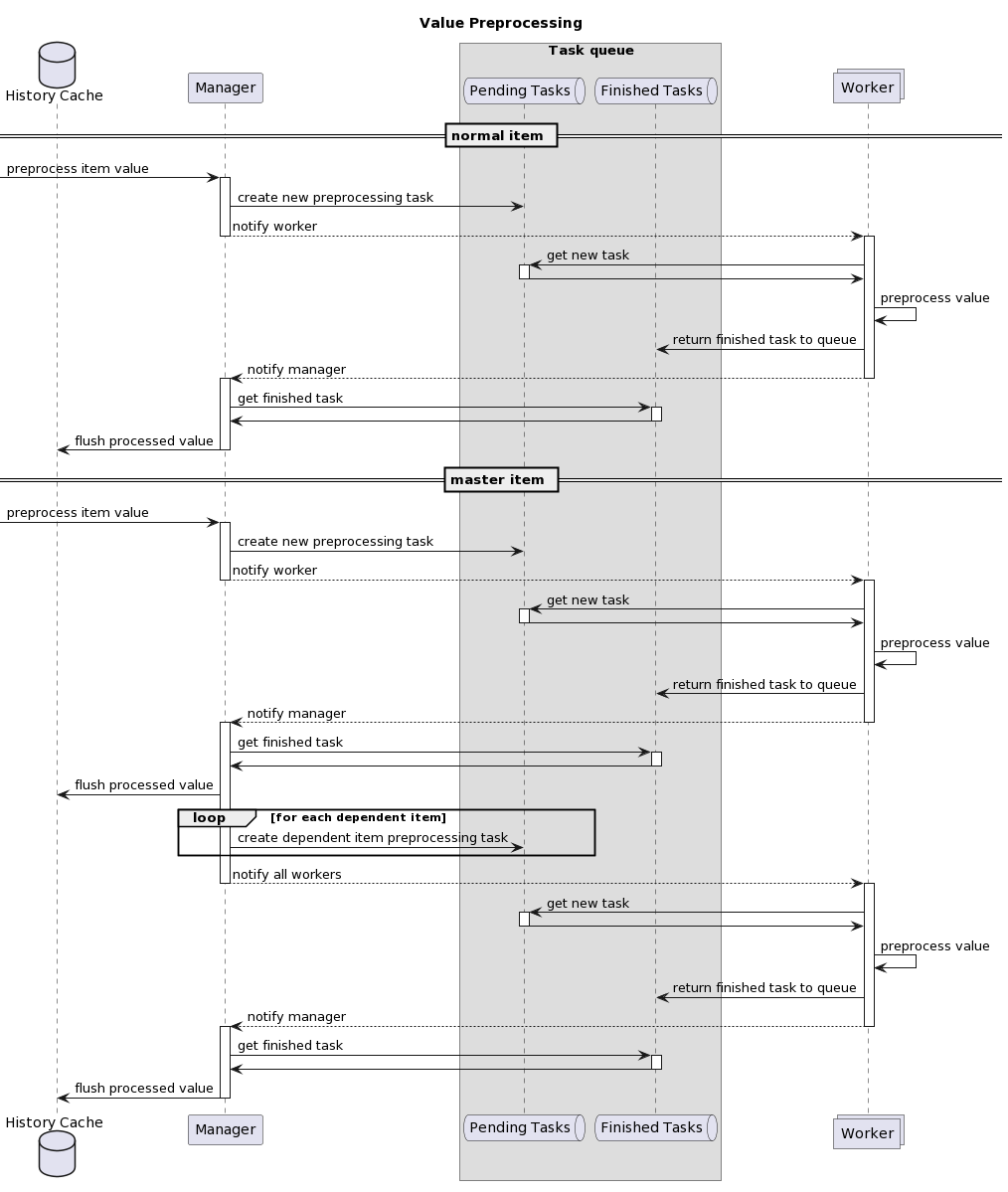
Merk op dat in het diagram de voorverwerking van het hoofditem iets vereenvoudigd is door de voorverwerkingscaching over te slaan.
Preprocessing queue
The preprocessing queue is organized as:
- the list of pending tasks:
- tasks created directly from value preprocessing requests in the order they were received.
- the list of immediate tasks (processed before pending tasks):
- testing tasks (created in response to item/preprocessing testing requests by the frontend)
- dependent item tasks
- sequence tasks (tasks that must be executed in a strict order):
- having preprocessing steps using the last value:
- change
- throttling
- JavaScript (bytecode caching)
- dependent item preprocessing caching
- having preprocessing steps using the last value:
- the list of finished tasks
Voorverwerkingscaching
Voorverwerkingscaching is geïntroduceerd om de prestaties van de voorverwerking te verbeteren voor meerdere afhankelijke items met vergelijkbare voorverwerkingsstappen (wat vaak voorkomt bij LLD-resultaten).
Caching wordt gedaan door één afhankelijk item voor te verwerken en enkele van de interne voorverwerkingsgegevens opnieuw te gebruiken voor de rest van de afhankelijke items. De voorverwerkingscache wordt alleen ondersteund voor de eerste voorverwerkingsstap van de volgende typen:
- Prometheus-patroon (indexen ingevoerd door metingen)
- JSONPath (parst de gegevens naar een objectboom en indexeert de eerste expressie
[?(@.path == "value")])
Voorverwerkingswerkers
Het Zabbix-serverconfiguratiebestand stelt gebruikers in staat om het aantal voorverwerkingswerkersthreads in te stellen. De configuratieparameter StartPreprocessors moet worden gebruikt om het aantal vooraf gestarte instanties van voorverwerkingswerkers in te stellen. Het optimale aantal voorverwerkingswerkers kan worden bepaald door vele factoren, waaronder het aantal "voorverwerkbare" items (items die vereisen dat er enige voorverwerkingsstappen worden uitgevoerd), het aantal processen voor gegevensverzameling, het gemiddelde aantal stappen voor itemvoorverwerking, enzovoort.
Maar ervan uitgaande dat er geen zware voorverwerkingsbewerkingen zijn zoals het parsen van grote XML/JSON-chunks, kan het aantal voorverwerkingswerkers overeenkomen met het totale aantal gegevensverzamelaars. Op deze manier zal er meestal (behalve in gevallen waarin gegevens van de verzamelaar in bulk binnenkomen) ten minste één onbezette voorverwerkingswerker zijn voor verzamelde gegevens.
Te veel gegevensverzamelingsprocessen (pollers, niet-bereikbare pollers, ODBC-pollers, HTTP-pollers, Java-pollers, pingers, trappers, proxypollers), samen met de IPMI-beheerder, SNMP-trapper en voorverwerkingswerkers, kunnen het bestanddescriptorlimiet per proces voor de voorverwerkingsbeheerder uitputten. Dit zal ertoe leiden dat de Zabbix-server stopt (meestal kort na het opstarten, maar soms kan het langer duren). Het configuratiebestand moet worden herzien of het limiet moet worden verhoogd om deze situatie te voorkomen.
Waardeverwerkingspijplijn
Het verwerken van itemwaarden wordt uitgevoerd in meerdere stappen (of fasen) door meerdere processen. Dit kan leiden tot:
- Een afhankelijk item kan waarden ontvangen, terwijl DE hoofdwaarde dat niet kan. Dit kan worden bereikt met het volgende gebruiksscenario:
- Het hoofditem heeft het waarde-type
UINT(een trapper-item kan worden gebruikt), het afhankelijke item heeft het waarde-typeTEXT. - Er zijn geen voorverwerkingsstappen vereist voor zowel het hoofd- als het afhankelijke item.
- Een tekstuele waarde (bijvoorbeeld "abc") moet aan het hoofditem worden doorgegeven.
- Aangezien er geen voorverwerkingsstappen zijn om uit te voeren, controleert de voorverwerkingsmanager of het hoofditem niet in de NIET ONDERSTEUNDE staat is en of de waarde is ingesteld (beide zijn waar) en voegt het afhankelijke item toe aan de wachtrij met dezelfde waarde als het hoofditem (aangezien er geen voorverwerkingsstappen zijn).
- Wanneer zowel het hoofditem als de afhankelijke items de fase voor het synchroniseren van de geschiedenis bereiken, wordt het hoofditem NIET ONDERSTEUND, vanwege de conversiefout van de waarde (tekstuele gegevens kunnen niet worden geconverteerd naar een niet-ondertekend geheel getal).
- Het hoofditem heeft het waarde-type
Als resultaat ontvangt het afhankelijke item een waarde, terwijl het hoofditem van staat verandert en NIET ONDERSTEUND wordt.
- Een afhankelijk item ontvangt een waarde die niet aanwezig is in de geschiedenis van het hoofditem. Het gebruiksscenario is zeer vergelijkbaar met het vorige scenario, behalve voor het type van het hoofditem. Bijvoorbeeld, als het type
CHARwordt gebruikt voor het hoofditem, dan zal de waarde van het hoofditem worden afgekapt in de fase van geschiedenissynchronisatie, terwijl afhankelijke items hun waarde ontvangen van de oorspronkelijke (niet afgekapte) waarde van het hoofditem.