
- #3 Wykrywanie niskopoziomowe
Przegląd
Wykrywanie niskopoziomowe umożliwia automatyczne tworzenie pozycji, wyzwalaczy i wykresów dla różnych elementów hosta. Na przykład, Zabbix może automatycznie rozpocząć monitorowanie systemów plików i interfejsów sieciowych maszyny, bez konieczności ręcznego tworzenia pozycji dla każdego systemu plików czy interfejsu. Dodatkowo istnieje możliwość takiego skonfigurowania Zabbix, by usuwał automatycznie zbędne elementy bazując na aktualnych wynikach wykrywania.
W Zabbix, dostępne są od razu trzy typy wykrywania pozycji:
- wykrywanie systemów plików;
- wykrywanie interfejsów sieciowych;
- wykrywanie OID SNMP.
Użytkownik może wprowadzić swój własny typ wykrywania, z wykorzystaniem protokołu JSON.
Ogólny schemat procesu wykrywania jest następujący.
Najpierw użytkownik tworzy regułę wykrywania w kolumnie "Konfiguracja" → "Szablony" → "Wykrywanie". Reguła wykrywania zawiera (1) pozycje, które wykrywają niezbędne elementy (na przykład, systemy plików czy interfejsy sieciowe) oraz (2) prototypy pozycji, wyzwalaczy i wykresów, które powinny być utworzone na podstawie tych pozycji.
Pozycja, która wykrywa wymagane elementy jest jak zwykła pozycja w innych miejscach: serwer pyta agenta Zabbix (lub inny ustawiony typ pozycji) o wartość pozycji, agent odpowiada wartością tekstową. Różnica polega na tym, że odpowiedź agenta powinna zawierać listę wykrytych elementów w specyficznym formacie JSON. Podczas, gdy szczegółowy format muszą znać jedynie programiści własnych rozwiązań wykrywania, trzeba wiedzieć, że zwracana jest lista par makro → wartość. Na przykład, pozycja "net.if.discovery" może zwrócić dwie pary: "{#IFNAME}" → "lo" i "{#IFNAME}" → "eth0".
Pozycje niskopoziomowego wykrywania - vfs.fs.discovery, net.if.discovery dostępne są od wersji agenta Zabbix 2.0.
W proxy Zabbix wartość zwracana przez reguły niskopoziomowego wykrywania jest ograniczona do 2048 bajtów przy IBM DB2.
Makra te następnie są używane w nazwach, kluczach i innych polach prototypów, które są podstawą do stworzenia rzeczywistych pozycji, wyzwalaczy i wykresów dla każdego wykrytego elementu. Makr tych można używać w:
- dla prototypów pozycji w
- nazwach
- kluczach
- OID SNMP
- formułach pozycji obliczanych
- skryptach SSH i Telnet
- parametrach pozycji monitorowania baz danych
- dla prototypów wyzwalaczy w
- nazwach
- wyrażeniach (zarówno przy odwołaniach do prototypu klucza pozycji jak i jako niezależne stałe)
- dla prototypów wykresów w
- nazwach
Gdy serwer otrzyma wartość dla pozycji wykrywania, szuka par makro → wartość i dla każdej pary, z wykorzystaniem odpowiednich prototypów, generuje rzeczywiste pozycje, wyzwalacze i wykresy. W przykładzie powyżej dla "net.if.discovery", serwer powinien wygenerować jeden zestaw pozycji, wyzwalaczy i wykresów dla interfejsu lokalnego "lo", i drugi zestaw dla interfejsu "eth0".
Następne sekcje ilustrują szczegółowo proces opisany powyżej, i mogą być używane jako schemat postępowania przy wykrywaniu systemów plików, interfejsów sieciowych czy identyfikatorów OID SNMP. Ostatnia sekcja opisuje format JSON dla pozycji wykrywania daje przykład własnej implementacji wykrywania systemu plików z wykorzystaniem skryptu Perl.
- Wykrywanie systemów plików
Żeby skonfigurować wykrywanie systemów plików, należy:
- Przejść do: Konfiguracja → Szablony
- Kliknąć na Wykrywanie w wierszu odpowiedniego szablonu

- Kliknąć na Utwórz regułę wykrywania w prawym górnym rogu ekranu
- Wypełnić szczegóły w formularzu
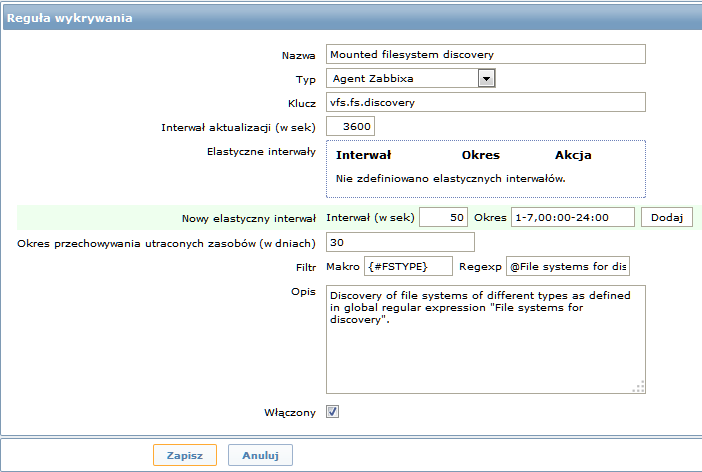
| Parametr | Opis |
|---|---|
| Nazwa | Nazwa reguły wykrywania. |
| Typ | Typ sprawdzenia do wykonania wykrywania; do wykrywania systemu plików powinien być ustawiony na Agent Zabbixa lub Agent Zabbixa (aktywny). |
| Klucz | Agent Zabbix na wielu platformach ma wbudowaną pozycję z kluczem "vfs.fs.discovery" (zobacz szczegółową listę wspieranych kluczy pozycji), która zwraca JSON z listą systemów plików obecnych w systemie, wraz z ich typami. |
| Interwał aktualizacji (w sek) | Pole to określa, jak często Zabbix przeprowadza wykrywanie. Na początek, gdy dopiero co ustawiamy wykrywanie systemu plików, można ustawić mały interwał, ale później, gdy już wiemy, że wykrywanie działa, można go ustawić na 30 minut lub więcej, gdyż systemy plików zbyt często się nie zmieniają. Uwaga: Wpisanie '0' spowoduje, że pozycja nie będzie pobierana. Jednakże, jeżeli jednocześnie istnieje elastyczny interwał z niezerową wartością, pozycja będzie pobierana podczas trwania elastycznego interwału. |
| Elastyczne interwały | Można utworzyć wyjątki od Interwału aktualizacji. Na przykład: Interwał: 0, Okres: 6-7,00:00-24:00 - wyłączy pobieranie na weekend. W przeciwnym przypadku użyty zostanie domyślny interwał aktualizacji. Można zdefiniować maksymalnie siedem elastycznych interwałów. Jeżeli kilka elastycznych interwałów będzie na siebie nachodzić, w tym czasie zostanie użyta najmniejsza wartość Interwału. Na temat formatu Okresu więcej informacji można znaleźć na stronie specyfikacji okresów czasu. Uwaga: Ustawienie na '0' spowoduje, że pozycja nie będzie pobierana podczas trwania elastycznego interwału, a jej pobieranie zostanie wznowione zgodnie z Interwałem aktualizacji po zakończeniu elastycznego interwału. |
| Okres przechowywania utraconych zasobów (w dniach) | Pole to pozwala określić ilość dni, przez które wykryty element pozostanie (nie będzie skasowany) po tym, jak jego status wykrywania zmieni się na "Nie można wykryć" (maksymalnie 3650 dni). Uwaga: Ustawienie na "0" spowoduje, że elementy będą usuwane natychmiast. Użycie "0" jest niewskazane, ponieważ zwykła pomyłka w filtrze może spowodować usunięcie pozycji z wszystkimi danymi historycznymi. |
| Filtr | Filtr może być użyty do generowania rzeczywistych pozycji, wyzwalaczy i wykresów dla wybranych systemów plików. Oczekuje Rozszerzonych Wyrażeń Regularnych POSIX. Przykładowo, jeżeli interesują nas tylko systemy plików C:, D: i E:, można wprowadzić {#FSNAME} w polu "Makro" i wyrażenie regularne "\C|\D|\E" w polu "Regexp". Możliwe jest również filtrowanie według typu systemu plików, używając makra {#FSTYPE} (n p. "\ext|\reiserfs"). W polu "Regexp" można wprowadzić wyrażenie regularne lub odwołanie do globalnego wyrażenia regularnego. Żeby przetestować wyrażenie regularne można użyć polecenia "grep -E", na przykład: `for f in ext2 nfs reiserfs smbfs; do echo $f | grep -E 'ext|^reiserfs' || echo "SKIP: $f"; done`{.bash}Należy zauważyć, że jeżeli w filtrze będzie brakowało jakiegoś makra, znalezione wpisy będą ignorowane. |
| Opis | Należy wprowadzić opis. |
| Włączony | Zaznaczenie tego pola włącza regułę, będzie ona przetwarzana. |
Jeżeli nazwy systemu plików różnią się tylko wielkościami liter, w przypadku MySQL, baza danych Zabbix musi być utworzona jako case-sensitive, w przeciwnym razie wykrywanie nie będzie prawidłowe.
Historia reguł wykrywania nie jest przechowywana.
Po utworzeniu reguły, należy przejść do pozycji dla tej reguły i utworzyć prototyp pozycji naciskając "Utwórz prototyp pozycji". Zauważ, jak jest używane makro {#FSNAME}, gdy wymagana jest nazwa systemu plików. Podczas przetwarzania reguły wykrywania, makro to jest zamieniane na wykryty system plików.

Jeżeli prototyp pozycji został utworzony ze stanem wyłączonym, zostanie dodana nowa wykryta pozycja, ale będzie ona wyłączona.
Można utworzyć kilka prototypów pozycji, dla każdej metryki systemu plików, która nas interesuje:

Następnie, w podobny sposób tworzymy prototypy wyzwalaczy:
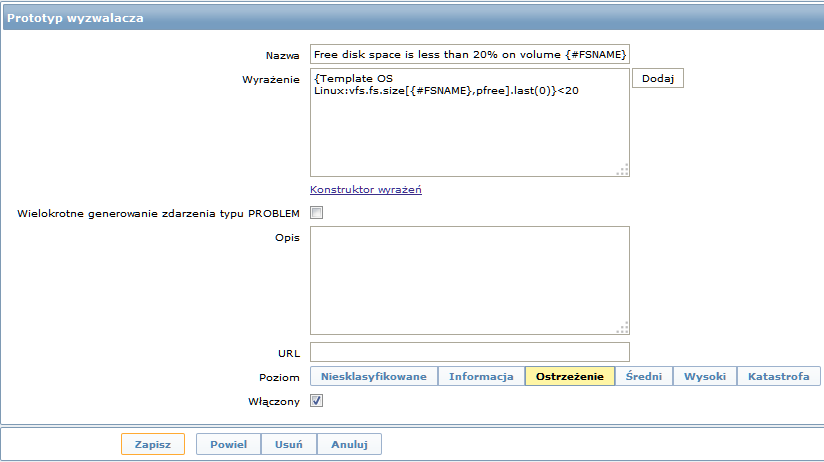
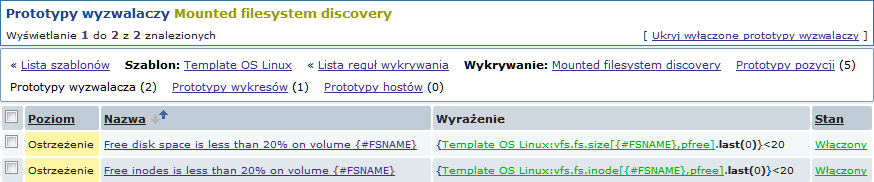
Oraz prototypy wykresów:
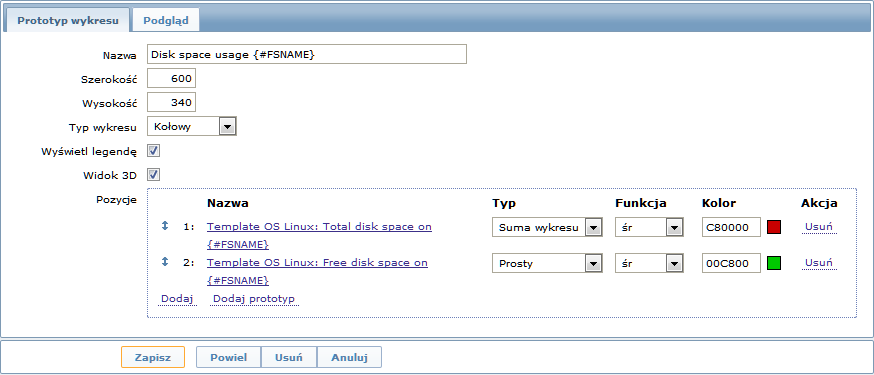

Ostatecznie, mamy utworzoną regułę wykrywania wyglądającą jak ta poniżej. Posiada pięć prototypów pozycji, dwa prototypy wyzwalaczy i jeden prototyp wykresu.

Uwaga: Żeby skonfigurować prototypy hostów, należy spojrzeć do konfiguracji prototypu hosta w monitorowaniu maszyn wirtualnych.
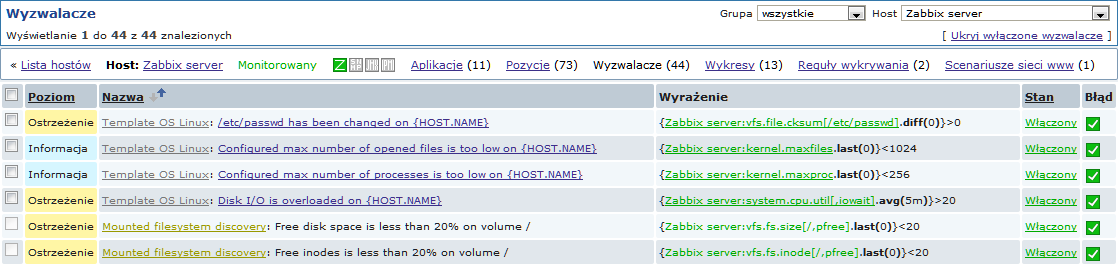
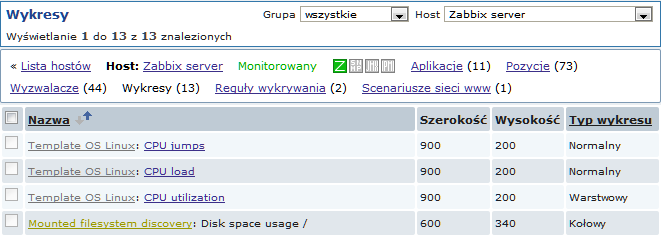
Ekrany poniżej ilustrują, jak wykryte pozycje, wyzwalacze i wykresy wyglądają w konfiguracji hosta. Wykryte elementy poprzedzone są złotym linkiem do reguły wykrywania, z której pochodzą.

Pozycje (tak jak i wyzwalacze i wykresy) utworzone przez niskopoziomowe reguły wykrywania, nie mogą być ręcznie usunięte. Jednakże, zostaną automatycznie usunięte, jeżeli wykryty element (system plików, interfejs, itp.) nie będzie już wykrywany (lub nie będzie już zgodny z filtrem). W tym przypadku pozycje będą usuwane po ilości dni zdefiniowanych w polu Okres przechowywania utraconych zasobów; wyzwalacze i wykresy będą usuwane od razu.
Gdy wykrywane elementy przejdą w stan 'Nie można wykryć', na liście pozycji pojawi się pomarańczowa ikona czasu życia. Po przesunięciu myszy nad znacznik pojawi się informacja o ilości dni pozostałych do usunięcia danej pozycji.

- Wykrywanie interfejsów sieciowych
Wykrywanie interfejsów sieciowych odbywa się identycznie, jak wykrywanie systemów plików, z wyjątkiem tego, że używa się klucza reguły wykrywania "net.if.discovery" zamiast "vfs.fs.discovery" i makra {#IFNAME} zamiast {#FSNAME} w filtrach i prototypach pozycji/wyzwalaczy/wykresów.
Przykłady prototypów pozycji, które można utworzyć bazując na "net.if.discovery": "net.if.in[{#IFNAME},bytes]", "net.if.out[{#IFNAME},bytes]".
Więcej informacji na temat filtrów można zobaczyć powyżej.
- Wykrywanie identyfikatorów OID SNMP
W tym przykładzie, wykonamy wykrywanie SNMP switch'a. Najpierw, należy przejść do "Konfiguracja" → "Szablony".
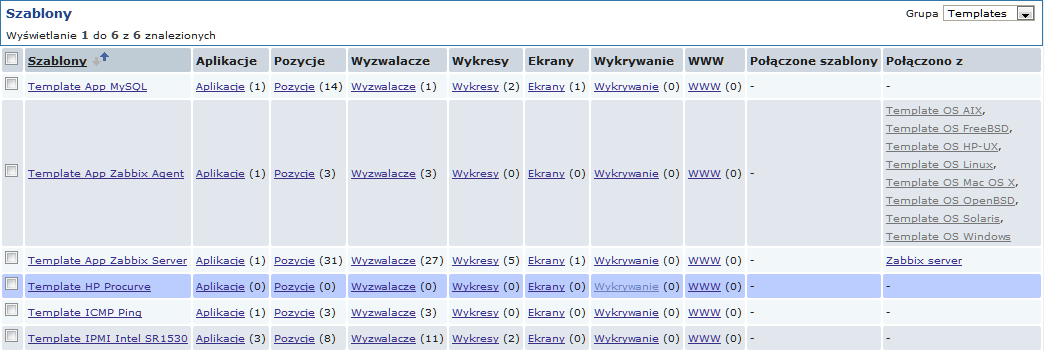
Żeby wprowadzić regułę wykrywania dla szablonu, należy kliknąć na link w kolumnie "Wykrywanie".
Następnie, nacisnąć "Utwórz regułę wykrywania" i wypełnić szczegóły w formularzu jak na poniższym ekranie.
W przeciwieństwie do wykrywania systemu plików lub interfejsów sieciowych, pozycja nie musi mieć klucza "snmp.discovery" - typ pozycji Agent SNMP jest wystarczający.
Podobnie jak w poprzednich przykładach, pozycja wykrywania generuje dwa makra dla każdego wykrytego elementu: {#SNMPINDEX} i {#SNMPVALUE}. W przypadku, gdy chcemy odfiltrować interfejsy loopback ze zwracanych wartości w polu filtra "Makro" należy wprowadzić "{#SNMPVALUE}" a w polu tekstowym "Regexp" należy wprowadzić wyrażenie regularne "\([\l]|l$)[\^o]?". Więcej informacji na temat filtrów można zobaczyć powyżej.
W polu "OID SNMP", należy wprowadzić OID, który pozwoli wygenerować wartość dla tych makr.
Żeby zrozumieć, co mamy na myśli, przedstawiamy snmpwalk z naszego switch'a:
$ snmpwalk -v 2c -c public 192.168.1.1 IF-MIB::ifDescr
IF-MIB::ifDescr.1 = STRING: WAN
IF-MIB::ifDescr.2 = STRING: LAN1
IF-MIB::ifDescr.3 = STRING: LAN2Makro {#SNMPINDEX} przyjmie wartość z części OID, która jest za ifDescr (w tym przykładzie: 1, 2, 3). Makro {#SNMPVALUE} przyjmie wartość odpowiadającą OID (tutaj: WAN, LAN1, LAN2). Zatem, nasza pozycja "snmp.discovery" zwróci trzy pary makro → wartość:
{#SNMPINDEX} → 1 {#SNMPVALUE} → WAN
{#SNMPINDEX} → 2 {#SNMPVALUE} → LAN1
{#SNMPINDEX} → 3 {#SNMPVALUE} → LAN2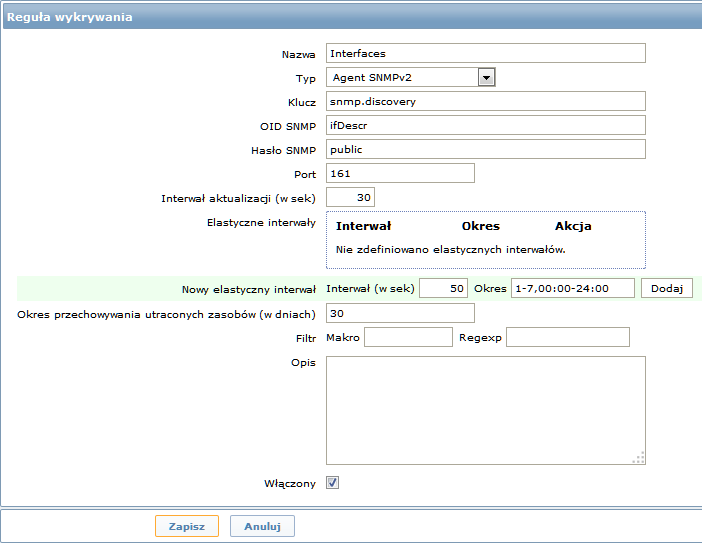
Kolejny ekran ilustruje, jak można użyć tych makr w prototypach pozycji:
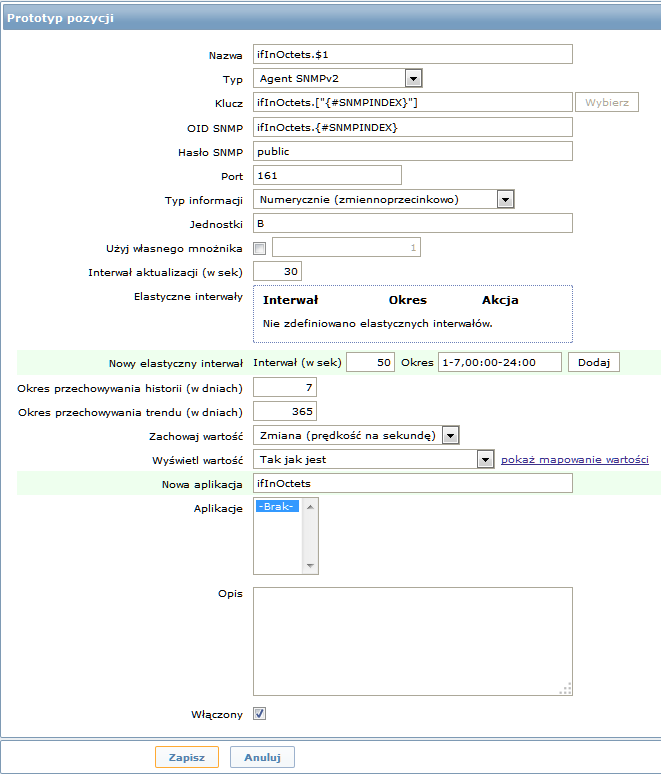
Ponownie, tworzymy tyle prototypów pozycji, ile trzeba:

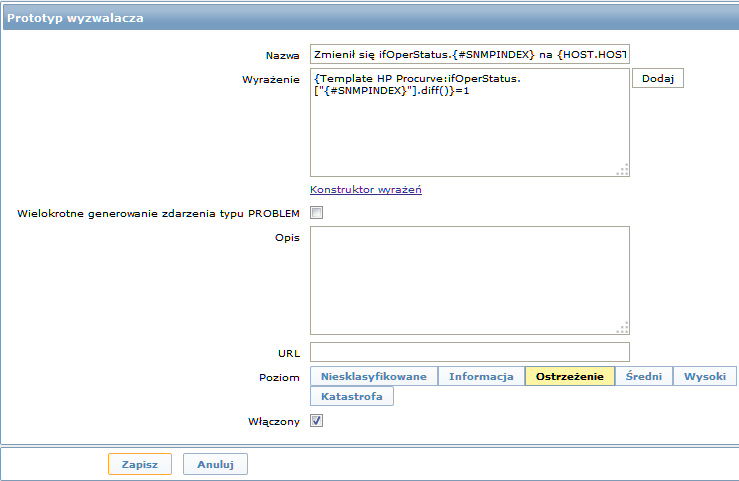
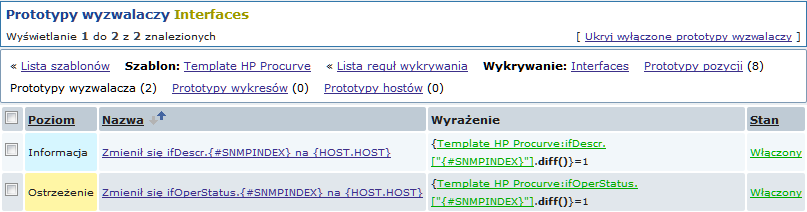
Jak również prototypów wyzwalaczy:
I prototypów wykresów:
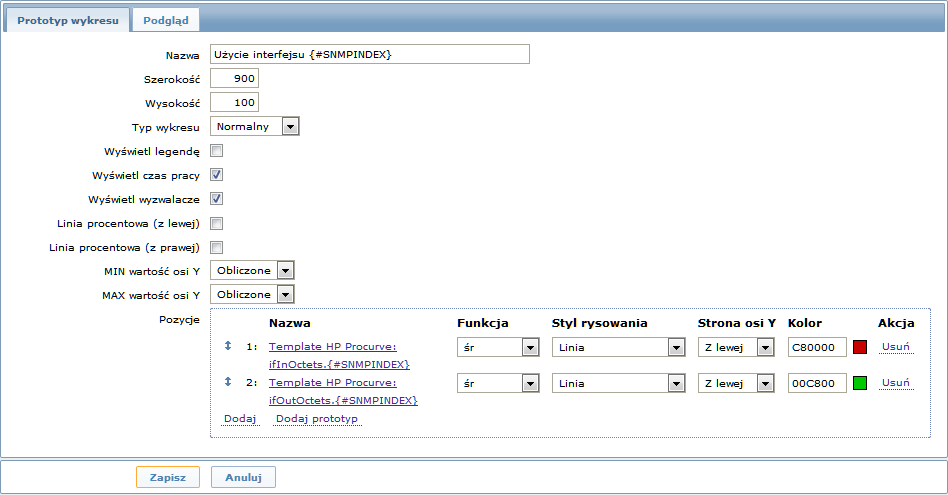
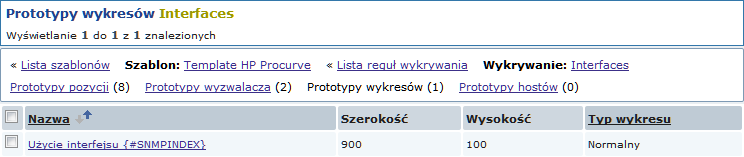
Podsumowanie naszej reguły wykrywania:

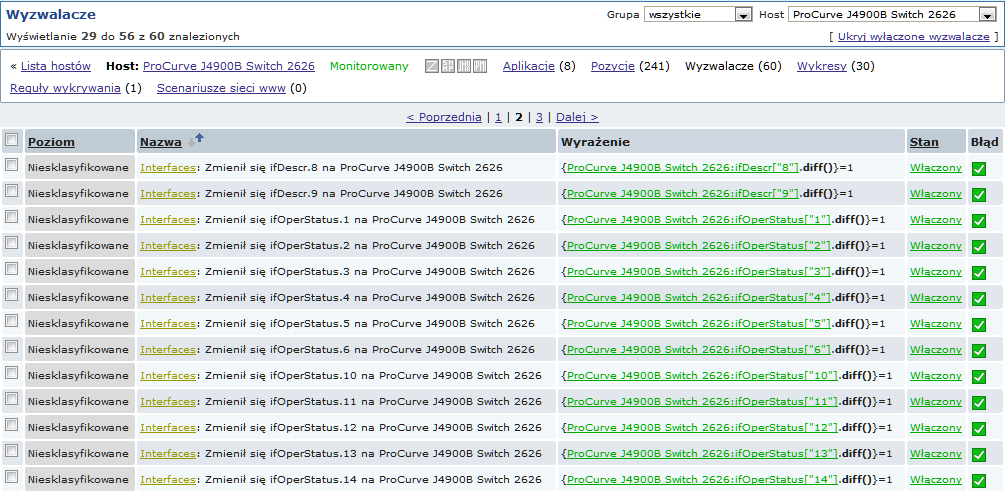
Po uruchomieniu serwera, utworzy rzeczywiste pozycje, wyzwalacze i wykresy, bazując na wartościach zwracanych przez "snmp.discovery". W konfiguracji hosta poprzedzone one będą złotym linkiem do reguły wykrywania, z której pochodzą.


- Tworzenie własnych niskopoziomowych reguł wykrywania
Istnieje również możliwość utworzenia całkowicie nowych niskopoziomowych reguł wykrywania, wykrywających dowolne typy elementów - na przykład, bazy danych na serwerze baz danych.
Żeby to zrobić, należy utworzyć własne pozycje zwracające JSON, określający znalezione obiekty i opcjonalnie - jakieś ich właściwości. Ilość makr dla elementu nie jest ograniczona - podczas gdy wbudowane reguły wykrywania zwracają jedno lub dwa makra (na przykład, dwa dla wykrywania systemu plików), możliwe jest zwrócenie większej ilości.
Wymagany format JSON najlepiej ilustruje przykład. Zakładamy, że mamy uruchomionego starego agenta Zabbix 1.8 (jednego z tych, który nie wspiera "vfs.fs.discovery"), ale nadal chcemy wykrywać systemy plików. poniżej przedstawiamy prosty skrypt Perl dla Linuxa, który wykrywa zamontowane systemy plików i zwraca JSON, który zawiera zarówno nazwę systemu plików jak i jego typ. Jedną z metod użycia jest wykorzystanie UserParameter z kluczem "vfs.fs.discovery_perl":
#!/usr/bin/perl
$first = 1;
print "{\n";
print "\t\"data\":[\n\n";
for (`cat /proc/mounts`)
{
($fsname, $fstype) = m/\S+ (\S+) (\S+)/;
$fsname =~ s!/!\\/!g;
print "\t,\n" if not $first;
$first = 0;
print "\t{\n";
print "\t\t\"{#FSNAME}\":\"$fsname\",\n";
print "\t\t\"{#FSTYPE}\":\"$fstype\"\n";
print "\t}\n";
}
print "\n\t]\n";
print "}\n";W nazwach niskopoziomowych reguł wykrywania
dozwolone są znaki 0-9 , A-Z , _ , .
Małe litery w nazwach nie są obsługiwane.
Przykładowe wyjście (przeformatowane dla wygody) pokazano poniżej. JSON dla własnych sprawdzeń wykrywania ma taki sam format.
{
"data":[
{ "{#FSNAME}":"\/", "{#FSTYPE}":"rootfs" },
{ "{#FSNAME}":"\/sys", "{#FSTYPE}":"sysfs" },
{ "{#FSNAME}":"\/proc", "{#FSTYPE}":"proc" },
{ "{#FSNAME}":"\/dev", "{#FSTYPE}":"devtmpfs" },
{ "{#FSNAME}":"\/dev\/pts", "{#FSTYPE}":"devpts" },
{ "{#FSNAME}":"\/", "{#FSTYPE}":"ext3" },
{ "{#FSNAME}":"\/lib\/init\/rw", "{#FSTYPE}":"tmpfs" },
{ "{#FSNAME}":"\/dev\/shm", "{#FSTYPE}":"tmpfs" },
{ "{#FSNAME}":"\/home", "{#FSTYPE}":"ext3" },
{ "{#FSNAME}":"\/tmp", "{#FSTYPE}":"ext3" },
{ "{#FSNAME}":"\/usr", "{#FSTYPE}":"ext3" },
{ "{#FSNAME}":"\/var", "{#FSTYPE}":"ext3" },
{ "{#FSNAME}":"\/sys\/fs\/fuse\/connections", "{#FSTYPE}":"fusectl" }
]
}Następnie, w polu "Filtr" reguły wykrywania można jako makro określić "{#FSTYPE}" a jako wyrażenie regularne można wprowadzić "rootfs|ext3".
Nie trzeba wykorzystywać nazw makr FSNAME/FSTYPE we własnych niskopoziomowych regułach wykrywania, można użyć dowolnych własnych nazw.