Documentation

Table of Contents
3 Eskalacje
Przegląd
Dzięki eskalacjom można utworzyć własne scenariusze wysyłania powiadomień lub wykonywania zdalnych poleceń.
W praktyce oznacza to, że:
- Użytkownicy mogą być informowani o problemach od razu
- Powiadomienia mogą być powtarzane aż do rozwiązania problemu
- Wysyłanie powiadomień można opóźnić
- Powiadomienia mogą być eskalowane do innych "wyższych" grup użytkowników
- Zdalne polecenia mogą być wykonywane od razu lub gdy problem nie jest rozwiązany przez dłuższy okres czasu
- Można wysyłać wiadomości odzyskania
Akcje są eskalowane w oparciu o krok eskalacji. Każdy krok ma długość trwania w czasie.
Można zdefiniować zarówno domyślną długość trwania jak i własną długość trwania dla indywidualnego kroku. Minimalna długość trwania jednego kroku eskalacji to 60 sekund.
Akcje takie jak wysyłanie wiadomości czy wykonanie poleceń, można uruchamiać z dowolnego kroku. Krok pierwszy jest zarezerwowany dla akcji natychmiastowych. Jeżeli chcemy opóźnić akcję, możemy ją przydzielić do późniejszego kroku. Dla każdego kroku można zdefiniować kilka akcji.
Ilość kroków eskalacji nie jest ograniczona.
Eskalacje definiowane są podczas konfigurowania operacji.
Różne aspekty zachowania eskalacji
Spróbujmy zobaczyć co się stanie w różnych sytuacjach, gdy akcja posiada kilka kroków eskalacji.
| Sytuacja | Zachowanie |
|---|---|
| Pewien host przeszedł w tryb utrzymania po tym, jak zostało wysłane powiadomienie o problemie | Wszystkie pozostałe kroki eskalacji będą wykonywane. Utrzymanie nie może zatrzymać operacji; utrzymanie ma jedynie wpływ na to, kiedy akcja ma być uruchomiona lub nie, a nie na operacje. |
| Okres czasu, zdefiniowany w warunku akcji Okres, zakończył się po wysłaniu pierwszego powiadomienia | Wszystkie pozostałe kroki eskalacji będą wykonywane. Warunek Okres nie może zatrzymać operacji; ma jedynie wpływ na to, kiedy akcja ma być uruchomiona lub nie, a nie na operacje. |
| Problem wystąpił podczas utrzymania i trwa (nie jest rozwiązany) po utrzymaniu | Wszystkie kroki eskalacji będą wykonane rozpoczynając od momentu ukończenia utrzymania. |
| Problem wystąpił podczas utrzymania bez danych i trwa (nie jest rozwiązany) po utrzymaniu | Musi zaczekać na odpalenie wyzwalacza, wtedy zostaną uruchomione wszystkie kroki eskalacji. |
| Różne eskalacje wystąpiły blisko siebie i nachodzą na siebie | Wykonanie każdej nowej eskalacji nadpisuje poprzednie eskalacje, ale przynajmniej jeden krok z poprzedniej eskalacji jest wykonywany. To zachowanie jest przydatne przy akcjach dotyczących zdarzeń, które są tworzone przy KAŻDYM wyliczeniu problemu w wyzwalaczu. |
| Akcja została wyłączona podczas trwania eskalacji (np podczas wysyłania wiadomości) | Wysyłana wiadomość zostanie wysłana, a zaraz po niej wysłana zostanie jeszcze jedna wiadomość eskalacji. Druga wiadomość będzie miała następujący tekst na początku: NOTE: Escalation cancelled: action '<Nazwa akcji>' disabled. Dzięki temu odbiorca zostanie poinformowany, że eskalacja została anulowana i nie będzie wykonanych więcej kroków. |
Przykłady eskalacji
Przykład 1
Wysyłanie powtarzającego się powiadomienia raz na 30 minut (ogółem 5 razy) do grupy 'MySQL Administrators'. Żeby skonfigurować:
- W zakładce Operacje, należy ustawić Czas trwania kroku domyślnej operacji na '1800' sekund (30 minut)
- Ustawić kroki eskalacji Od '1' Do '5'
- Wybrać grupę 'MySQL Administrators' jako odbiorcę wiadomości
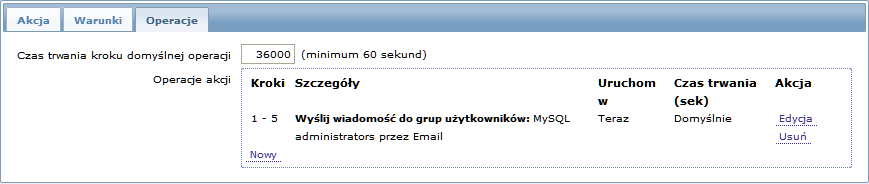
Wiadomości wysłane zostaną w 0:00, 0:30, 1:00, 1:30, 2:00 godzinie po wystąpieniu problemu (chyba, że problem zostanie rozwiązany wcześniej).
Jeżeli problem zostanie rozwiązany i skonfigurowano wiadomość odzyskania, zostanie ona wysłana do wszystkich, którzy odebrali przynajmniej jedną wiadomość ze scenariusza eskalacji.
Jeżeli wyzwalacz, który wygenerował aktywną eskalację zostanie wyłączony, Zabbix wyśle wiadomość informującą o tym do wszystkich, którzy otrzymali już powiadomienia.
Przykład 2
Wysyłanie opóźnionych powiadomień o długo występującym problemie. Żeby skonfigurować:
- W zakładce Operacje, należy ustawić Czas trwania kroku domyślnej operacji na '36000' sekund (10 godzin)
- Ustawić kroki eskalacji Od '2' Do '2'
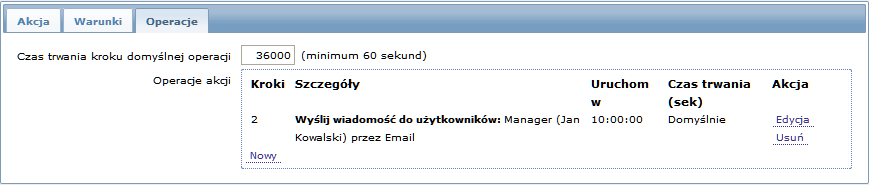
Powiadomienie zostanie wysłane jedynie w Kroku 2 scenariusza eskalacji, lub 10 godzin po wystąpieniu problemu.
Można zmienić tekst wiadomości na przykład tak: 'Problem trwa od 10 godzin'.
Przykład 3
Eskalacja problemu do Szefa.
W pierwszym przykładzie powyżej skonfigurowaliśmy okresowe wysyłanie wiadomości do administratorów MySQL. W tym przypadku, administratorzy otrzymają cztery wiadomości, a następnie problem będzie eskalowany do menadżera baz danych. Należy zauważyć, że menadżer otrzyma wiadomość jedynie wtedy, gdy problem nie zostanie jeszcze potwierdzony, przypuszczalnie nikt nad nim nie pracuje.

Zauważmy, że w wiadomości użyto makra {ESC.HISTORY}. Makro będzie zawierało informacje o wszystkich poprzednio wykonanych krokach tej eskalacji, takich jak wysłane wiadomości czy wykonane polecenia.
Przykład 4
Bardziej skomplikowany scenariusz. Po kilku wiadomościach do administratorów MySQL i eskalacji do menadżera, Zabbix spróbuje zrestartować bazę danych MySQL. Nastąpi to, jeżeli problem istnieje od 2:30 godzin i nie został potwierdzony.
Jeżeli problem nadal istnieje, po kolejnych 30 minutach Zabbix wyśle wiadomość do wszystkich użytkowników gości.
Jeżeli to nie pomoże, po kolejnej godzinie Zabbix zrestartuje serwer z bazą danych MySQL (drugie zdalne polecenie) używając poleceń IPMI.

Przykład 5
Eskalacja z kilkoma operacjami przydzielonymi do jednego kroku i z własnymi interwałami. Domyślnie czas trwania kroku to 30 minut.

Powiadomienia będą wysyłane następująco:
- do administratorów MySQL w 0:00, 0:30, 1:00, 1:30 po wystąpieniu problemu
- do menadżera bazy danych w 2:00 i 2:10 (a nie w 3:00; kroki 5 i 6 nachodzą na siebie, Krótszy własny okres trwania kroku równy 600 sekund w następnej operacji nadpisuje dłuższy okres trwania równy 3600 sekund)
- do administratorów Zabbix w 2:00, 2:10, 2:20 po wystąpieniu problemu (działa własny okres trwania 600 sekund)
- do użytkowników gości w 4:00 godziny po wystąpieniu problemu (pomiędzy krokami 8 i 11 jest domyślny okres trwania równy 30 minut)