
3 Escalonamento
Visão geral
Com o recurso de escalonamento você pode criar cenários personalizados de quando enviar uma mensagem ou executar um comando remoto.
Situações comuns de utilização:
- Usuários precisam ser informados sobre novos incidentes imediatamente
- Notificações precisam ser reenviadas enquanto o incidente não for resolvido
- O envio de uma notificação precisa ser atrasado
- As notificações precisam ser escalonadas para um grupo mais especializado
- Comandos remotos podem ser executados imediatamente, entretanto, só é desejada a execução automática se o incidente não for resolvido em determinado tempo
- Mensagens de recuperação precisam ser enviadas
Ações são escaladas usando os passos de escalonamento. Cada passo pode ter sua própria duração.
Você pode definir tanto a duração padrão quanto a duração de um passo em específico, o tempo mínimo em ambos os casos é de 60 segundos.
A ação pode começar com uma operação simples de envio de notificação ou execução de comando remoto. O primeiro passo é para ações imediatas, se você precisa atrasar a operação, atribua a ela um número de passo superior ao 1. Para cada passo diferentes operações podem ser definidas.
Não existe limite de passos de escalonamento.
O escalonamento é definido durante a configuração das operações.
Aspectos diversos sobre escalonamento
Vamos considerar que uma mesma ação contenha diversos passos de escalonamento para diferentes situações.
| Situação | Comportamento |
|---|---|
| O host em questão entra em manutenção após a notificação do início do incidente ser enviada | Todos os escalonamentos restantes serão executados. O processo de manutenção programada não para as operações, afeta somente o início / fim das ações e se uma ação já está em execução ela não será afetada pela manutenção. |
| O Intervalo definido na condição da ação termina após a notificação inicial ser enviada | Todos os passos subsequentes de escalonamento são executados. A condição de Intervalo não termina com as operações; esta condição afeta o início das ações, não das operações. |
| Um incidente inicia durante um período de manutenção e continua como não solucionado após o final da manutenção | Todos os passos de escalonamento são executados a partir do momento final da manutenção. |
| Um problema inicia durante um período de manutenção sem coleta de dados e continua como não resolvido após a manutenção terminar | Será necessário aguardar que a trigger seja disparada, antes que os processos de escalonamento sejam executados. |
| Diferentes escalonamentos com estreita sucessão e sobreposição | A execução de cada novo escalonamento substitui o anterior, mas pelo menos um passo de escalonamento sempre será executado no escalonamento anterior. Este comportamento é relevante em ações sobre eventos que são criados em todas as mudanças para o estado de incidente em triggers. |
| Uma ação é desabilitada durante o processo de escalonamento (durante o processo de envio de mensagem por exemplo) | A mensagem atual e a próxima mensagem do escalonamento ainda serão enviadas. A mensagem seguinte terá o seguinte texto no início do corpo: NOTE: Escalation cancelled: action '<Action name>' disabled. Isso ocorre para que o destinatário saiba o motivo pelo qual o escalonamento não será executado. |
Exemplos de escalonamento
Exemplo 1
Enviando uma notificação repetida a cada 30 minutos (até um máximo de 5) para o grupo 'MySQL Administrators':
- Na aba Operações, defina a Duração padrão do passo da operação para '1800' segundos (30 minutos)
- Defina os passos do escalonamento de '1' ate '5'
- Selecione o grupo 'MySQL Administrators' como destinatário da mensagem
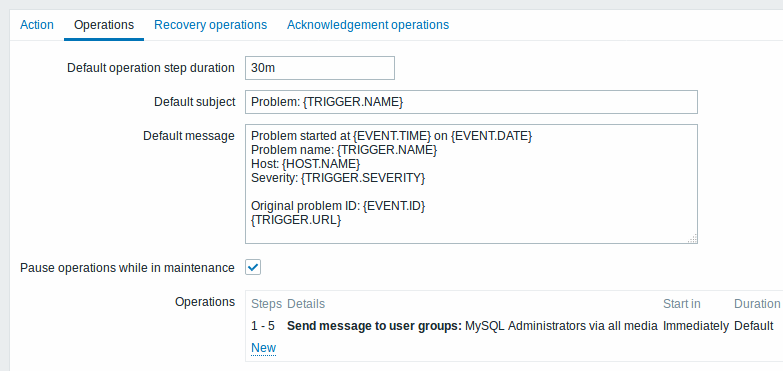
Nofificações serão enviadas, contando a partir do momento que o incidente inicia, às 00:00, 0:30, 1:00, 1:30, 2:00 horas (a não sere que o incidente seja resolvido antes).
Se o problema for resolvido e uma mensagem de recuperação for configurada, esta será enviada a todos que receberam pelo menos uma das mensagens do escalonamento.
Se a trigger que gerou o escalonamento for desabilitada, o Zabbix enviará uma mensagem sobre isso para todos que já receberam alguma notificação.
Exemplo 2
Enviando uma notificação com atraso, informando um longo período de problema:
- Na aba de Operações, defina a Duração padrão do passo da operação para '36000' segundos (10 horas)
- Defina os passos do escalonamento de '2' ate '2'
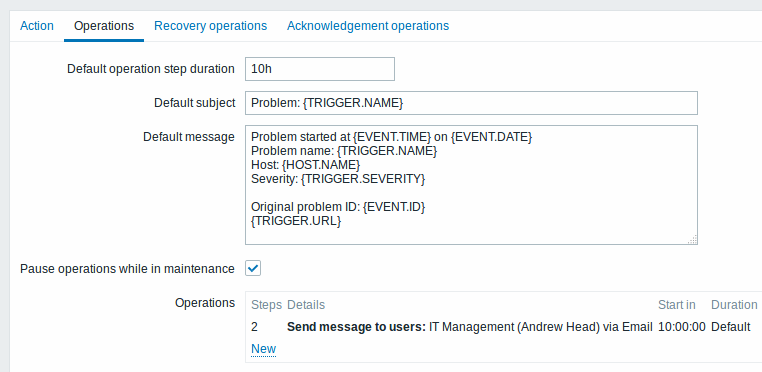
A notificação irá aguardar até que o cenário 2 ocorra (neste caso 10 horas após o início do incidente).
Você pode customizar esta mensagem, por exemplo, para algo como: 'O incidente já ocorre a mais de 10 horas'.
Exemplo 3
Escalando o problema para o chefe.
No primeiro exemplo acima nós configuramos o envio periódico de mensagens para o grupo 'MySQL administrators'. Agora vamos configurar para que os Administradores recebam quatro mensagens de notificação antes do problema ser escalado para o gerente de bancos de dados. Observe que o gerente só receberá a mensagem se o problema não tiver sido reconhecido também (o que indica, teoricamente, que ninguém está tratando o incidente).
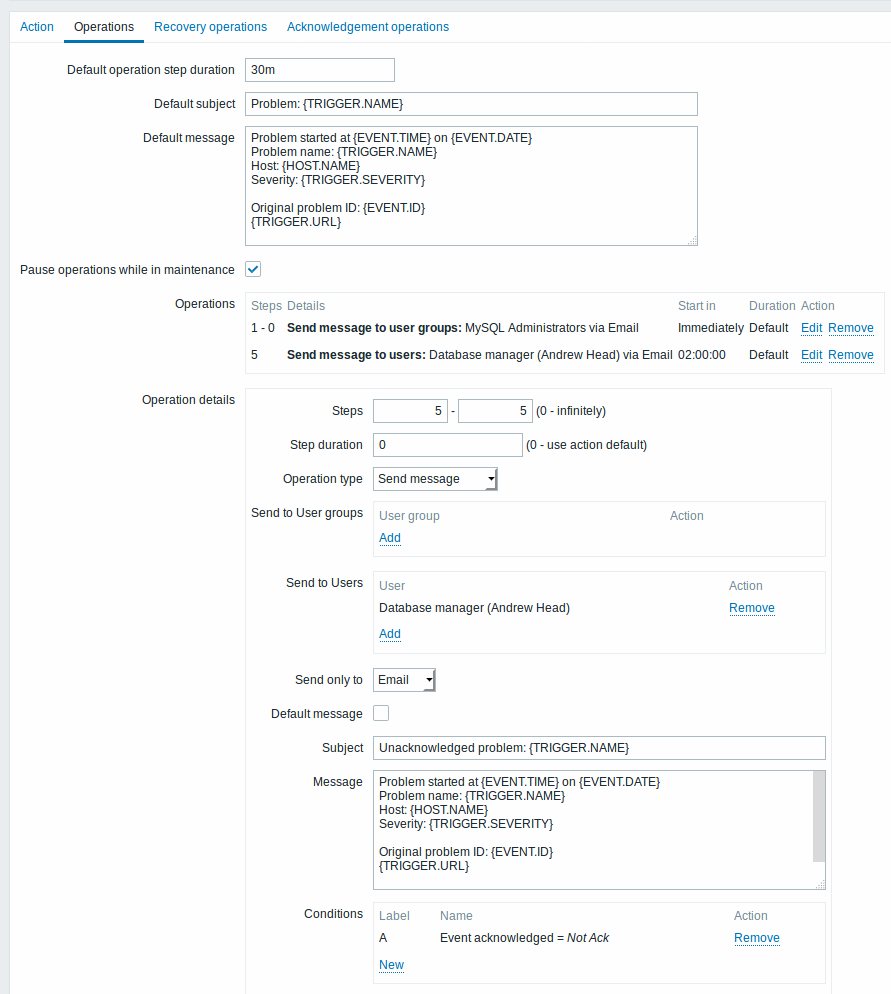
Observe o uso da macro {ESC.HISTORY} na mensagem, ela conterá informações sobre todos os passos que já ocorreram. Neste caso as notificações enviadas e os comandos executados.
Exemplo 4
Um cenário mais complexo. Após múltiplas mensagens ao grupo 'MySQL administrators' e ter escalado o problema ao gerente, o Zabbix irá tentar reiniciar o banco de dados MySQL. Isso irá ocorrer se o problema já existir a mais de 2:30 horas e não tiver sido reconhecido.
Se o problema ainda existir, após outros 30 minutos, o Zabbix irá enviar uma mensagem para todos os usuários convidados.
Se isso não ajudar, após outra hora, o Zabbix irá reiniciar o servidor com o banco MySQL (um segundo comando) usando o protocolo IPMI.
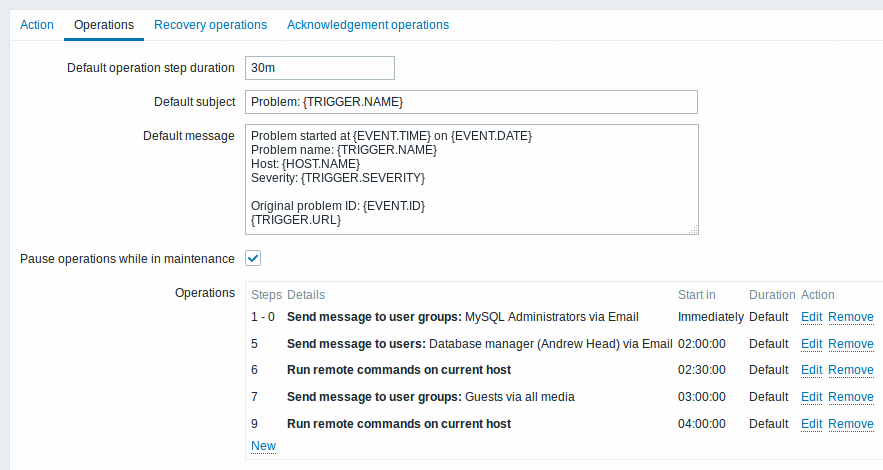
Exemplo 5
Um escalonamento com diversas operações associadas a um passo e durações diferentes. A operação padrão é de 30 minutos.
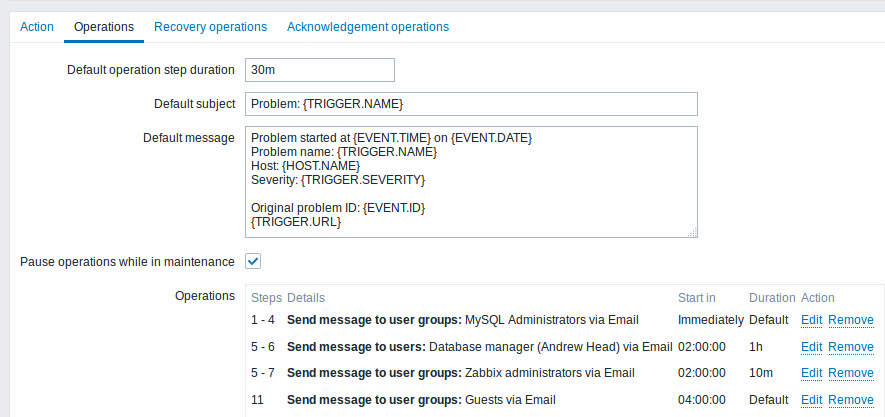
As notificações serão enviadas conforme descrito a seguir:
- Para o grupo 'MySQL administrators' às 0:00, 0:30, 1:00, 1:30 após o problema começar
- Para o grupo 'Database manager' às 2:00 e 2:10 (não às 3:00; vendo que os passos 5 e 6 se sobrepõe com a próxima operação, a menor duração de passo configurada é de 600 segundos e por isso o passo corrente teve o passo sobreposto)
- Para o grupo 'Zabbix administrators' às 2:00, 2:10, 2:20 após o problema iniciar (a duração customizada de 600 segundos funcionou)
- Para o grupo 'Convidados' 4:00 horas após o problema iniciar (a duração padrão de 30 minutos retornando entre os passos 8 e 11)